 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Algorithms and Lower Bounds for Linear Regression with Norm Constraints
Oct 25, 2021

Lasso and Ridge are important minimization problems in machine learning and statistics. They are versions of linear regression with squared loss where the vector $\theta\in\mathbb{R}^d$ of coefficients is constrained in either $\ell_1$-norm (for Lasso) or in $\ell_2$-norm (for Ridge). We study the complexity of quantum algorithms for finding $\varepsilon$-minimizers for these minimization problems. We show that for Lasso we can get a quadratic quantum speedup in terms of $d$ by speeding up the cost-per-iteration of the Frank-Wolfe algorithm, while for Ridge the best quantum algorithms are linear in $d$, as are the best classical algorithms.
Improved Quantum Boosting
Sep 17, 2020Boosting is a general method to convert a weak learner (which generates hypotheses that are just slightly better than random) into a strong learner (which generates hypotheses that are much better than random). Recently, Arunachalam and Maity gave the first quantum improvement for boosting, by combining Freund and Schapire's AdaBoost algorithm with a quantum algorithm for approximate counting. Their booster is faster than classical boosting as a function of the VC-dimension of the weak learner's hypothesis class, but worse as a function of the quality of the weak learner. In this paper we give a substantially faster and simpler quantum boosting algorithm, based on Servedio's SmoothBoost algorithm.
Two new results about quantum exact learning
Sep 30, 2018We present two new results about exact learning by quantum computers. First, we show how to exactly learn a $k$-Fourier-sparse $n$-bit Boolean function from $O(k^{1.5}(\log k)^2)$ uniform quantum examples for that function. This improves over the bound of $\widetilde{\Theta}(kn)$ uniformly random \emph{classical} examples (Haviv and Regev, CCC'15). Second, we show that if a concept class $\mathcal{C}$ can be exactly learned using $Q$ quantum membership queries, then it can also be learned using $O\left(\frac{Q^2}{\log Q}\log|\mathcal{C}|\right)$ \emph{classical} membership queries. This improves the previous-best simulation result (Servedio and Gortler, SICOMP'04) by a $\log Q$-factor.
A Survey of Quantum Learning Theory
Jul 28, 2017This paper surveys quantum learning theory: the theoretical aspects of machine learning using quantum computers. We describe the main results known for three models of learning: exact learning from membership queries, and Probably Approximately Correct (PAC) and agnostic learning from classical or quantum examples.
Optimal Quantum Sample Complexity of Learning Algorithms
Jun 06, 2017$ \newcommand{\eps}{\varepsilon} $In learning theory, the VC dimension of a concept class $C$ is the most common way to measure its "richness." In the PAC model $$ \Theta\Big(\frac{d}{\eps} + \frac{\log(1/\delta)}{\eps}\Big) $$ examples are necessary and sufficient for a learner to output, with probability $1-\delta$, a hypothesis $h$ that is $\eps$-close to the target concept $c$. In the related agnostic model, where the samples need not come from a $c\in C$, we know that $$ \Theta\Big(\frac{d}{\eps^2} + \frac{\log(1/\delta)}{\eps^2}\Big) $$ examples are necessary and sufficient to output an hypothesis $h\in C$ whose error is at most $\eps$ worse than the best concept in $C$. Here we analyze quantum sample complexity, where each example is a coherent quantum state. This model was introduced by Bshouty and Jackson, who showed that quantum examples are more powerful than classical examples in some fixed-distribution settings. However, Atici and Servedio, improved by Zhang, showed that in the PAC setting, quantum examples cannot be much more powerful: the required number of quantum examples is $$ \Omega\Big(\frac{d^{1-\eta}}{\eps} + d + \frac{\log(1/\delta)}{\eps}\Big)\mbox{ for all }\eta> 0. $$ Our main result is that quantum and classical sample complexity are in fact equal up to constant factors in both the PAC and agnostic models. We give two approaches. The first is a fairly simple information-theoretic argument that yields the above two classical bounds and yields the same bounds for quantum sample complexity up to a $\log(d/\eps)$ factor. We then give a second approach that avoids the log-factor loss, based on analyzing the behavior of the "Pretty Good Measurement" on the quantum state identification problems that correspond to learning. This shows classical and quantum sample complexity are equal up to constant factors.
Algorithmic Clustering of Music
Mar 24, 2003
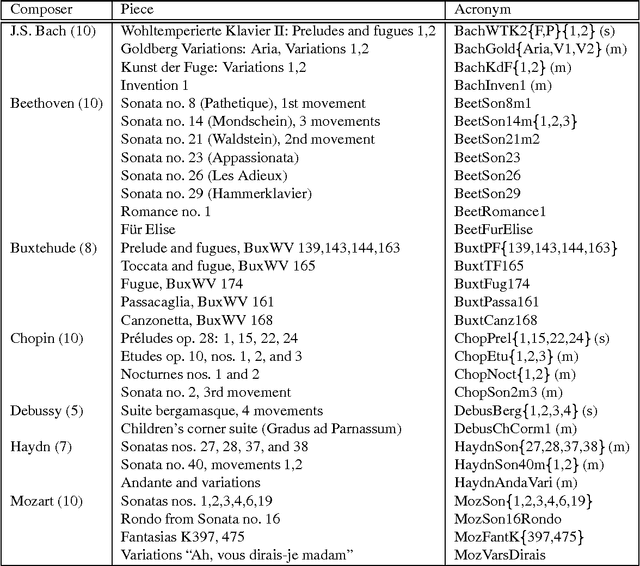

We present a fully automatic method for music classification, based only on compression of strings that represent the music pieces. The method uses no background knowledge about music whatsoever: it is completely general and can, without change, be used in different areas like linguistic classification and genomics. It is based on an ideal theory of the information content in individual objects (Kolmogorov complexity), information distance, and a universal similarity metric. Experiments show that the method distinguishes reasonably well between various musical genres and can even cluster pieces by composer.