 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagiC: Evaluating Multimodal Cognition Toward Grounded Visual Reasoning
Jul 09, 2025Recent advances in large vision-language models have led to impressive performance in visual question answering and multimodal reasoning. However, it remains unclear whether these models genuinely perform grounded visual reasoning or rely on superficial patterns and dataset biases. In this work, we introduce MagiC, a comprehensive benchmark designed to evaluate grounded multimodal cognition, assessing not only answer accuracy but also the quality of step-by-step reasoning and its alignment with relevant visual evidence. Our benchmark includes approximately 5,500 weakly supervised QA examples generated from strong model outputs and 900 human-curated examples with fine-grained annotations, including answers, rationales, and bounding box groundings. We evaluate 15 vision-language models ranging from 7B to 70B parameters across four dimensions: final answer correctness, reasoning validity, grounding fidelity, and self-correction ability. MagiC further includes diagnostic settings to probe model robustness under adversarial visual cues and assess their capacity for introspective error correction. We introduce new metrics such as MagiScore and StepSense, and provide comprehensive analyses that reveal key limitations and opportunities in current approaches to grounded visual reasoning.
EmoGist: Efficient In-Context Learning for Visual Emotion Understanding
May 20, 2025In this paper, we introduce EmoGist, a training-free, in-context learning method for performing visual emotion classification with LVLMs. The key intuition of our approach is that context-dependent definition of emotion labels could allow more accurate predictions of emotions, as the ways in which emotions manifest within images are highly context dependent and nuanced. EmoGist pre-generates multiple explanations of emotion labels, by analyzing the clusters of example images belonging to each category. At test time, we retrieve a version of explanation based on embedding similarity, and feed it to a fast VLM for classification. Through our experiments, we show that EmoGist allows up to 13 points improvement in micro F1 scores with the multi-label Memotion dataset, and up to 8 points in macro F1 in the multi-class FI dataset.
Encoding Multi-Domain Scientific Papers by Ensembling Multiple CLS Tokens
Sep 08, 2023Many useful tasks on scientific documents, such as topic classification and citation prediction, involve corpora that span multiple scientific domains. Typically, such tasks are accomplished by representing the text with a vector embedding obtained from a Transformer's single CLS token. In this paper, we argue that using multiple CLS tokens could make a Transformer better specialize to multiple scientific domains. We present Multi2SPE: it encourages each of multiple CLS tokens to learn diverse ways of aggregating token embeddings, then sums them up together to create a single vector representation. We also propose our new multi-domain benchmark, Multi-SciDocs, to test scientific paper vector encoders under multi-domain settings. We show that Multi2SPE reduces error by up to 25 percent in multi-domain citation prediction, while requiring only a negligible amount of computation in addition to one BERT forward pass.
Open Aspect Target Sentiment Classification with Natural Language Prompts
Sep 08, 2021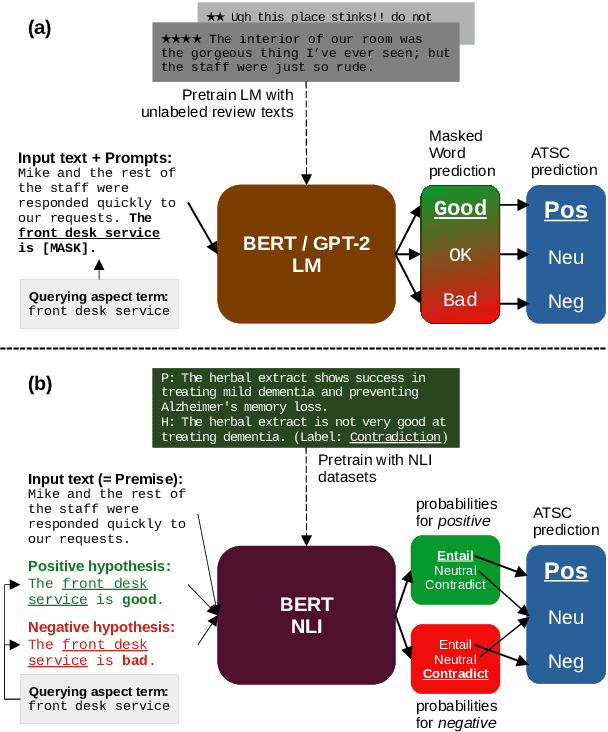
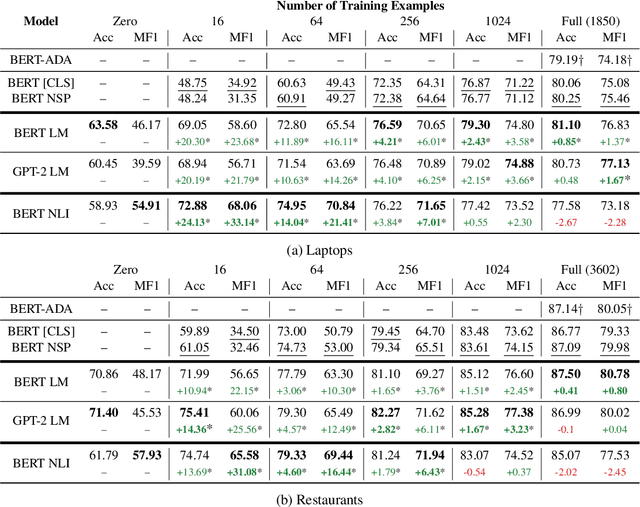
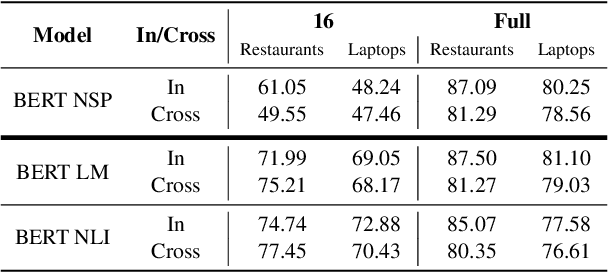
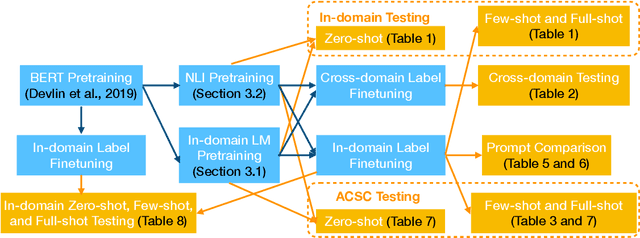
For many business applications, we often seek to analyze sentiments associated with any arbitrary aspects of commercial products, despite having a very limited amount of labels or even without any labels at all. However, existing aspect target sentiment classification (ATSC) models are not trainable if annotated datasets are not available. Even with labeled data, they fall short of reaching satisfactory performance. To address this, we propose simple approaches that better solve ATSC with natural language prompts, enabling the task under zero-shot cases and enhancing supervised settings, especially for few-shot cases. Under the few-shot setting for SemEval 2014 Task 4 laptop domain, our method of reformulating ATSC as an NLI task outperforms supervised SOTA approaches by up to 24.13 accuracy points and 33.14 macro F1 points. Moreover, we demonstrate that our prompts could handle implicitly stated aspects as well: our models reach about 77% accuracy on detecting sentiments for aspect categories (e.g., food), which do not necessarily appear within the text, even though we trained the models only with explicitly mentioned aspect terms (e.g., fajitas) from just 16 reviews - while the accuracy of the no-prompt baseline is only around 65%.
Solving Bayesian Network Structure Learning Problem with Integer Linear Programming
Jul 06, 2020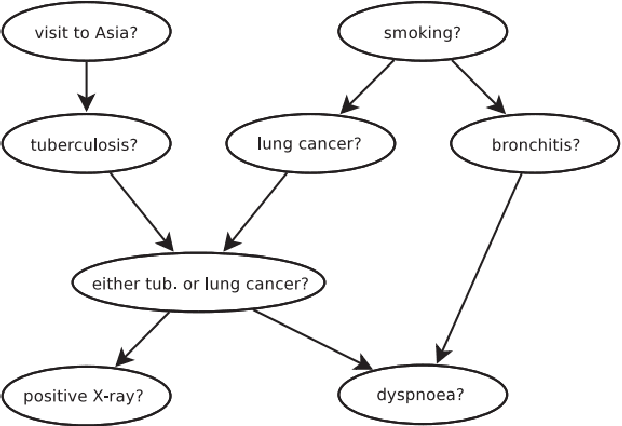
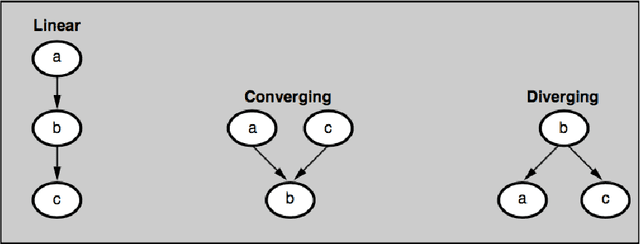
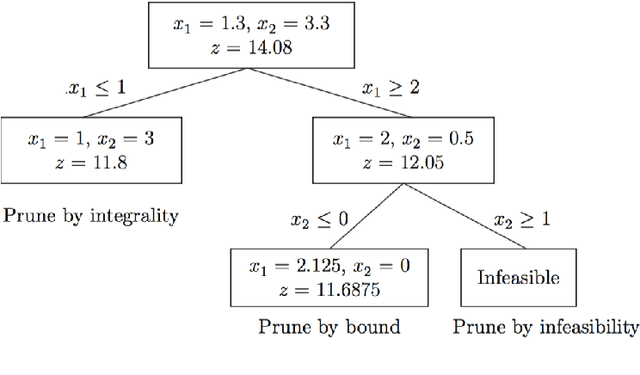
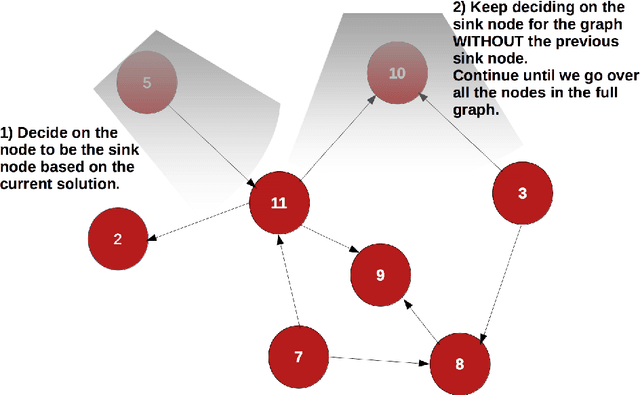
This dissertation investigates integer linear programming (ILP) formulation of Bayesian Network structure learning problem. We review the definition and key properties of Bayesian network and explain score metrics used to measure how well certain Bayesian network structure fits the dataset. We outline the integer linear programming formulation based on the decomposability of score metrics. In order to ensure acyclicity of the structure, we add ``cluster constraints'' developed specifically for Bayesian network, in addition to cycle constraints applicable to directed acyclic graphs in general. Since there would be exponential number of these constraints if we specify them fully, we explain the methods to add them as cutting planes without declaring them all in the initial model. Also, we develop a heuristic algorithm that finds a feasible solution based on the idea of sink node on directed acyclic graphs. We implemented the ILP formulation and cutting planes as a \textsf{Python} package, and present the results of experiments with different settings on reference datasets.
Qualitative Analysis of Monte Carlo Dropout
Jul 03, 2020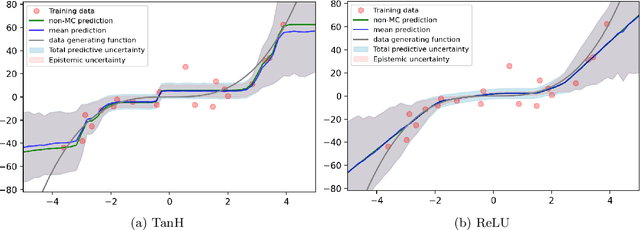



In this report, we present qualitative analysis of Monte Carlo (MC) dropout method for measuring model uncertainty in neural network (NN) models. We first consider the sources of uncertainty in NNs, and briefly review Bayesian Neural Networks (BNN), the group of Bayesian approaches to tackle uncertainties in NNs. After presenting mathematical formulation of MC dropout, we proceed to suggesting potential benefits and associated costs for using MC dropout in typical NN models, with the results from our experiments.