 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Distributed k-Means with a Small Number of Rounds
Jan 31, 2022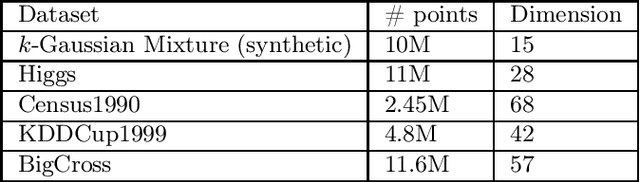
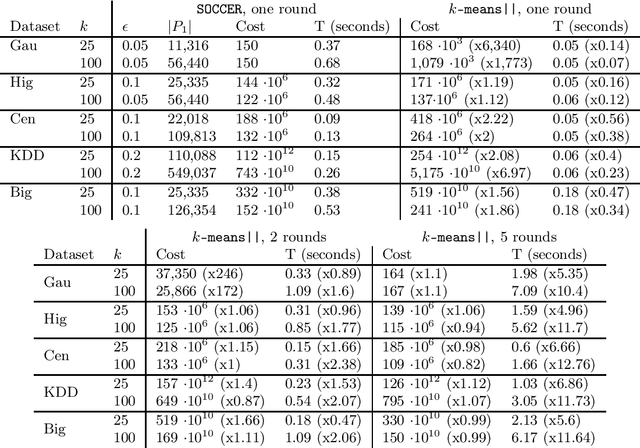
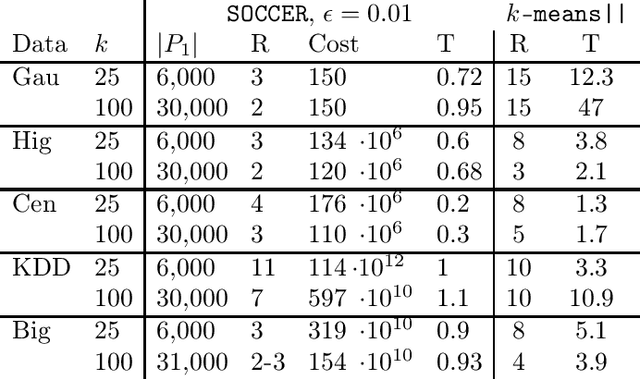
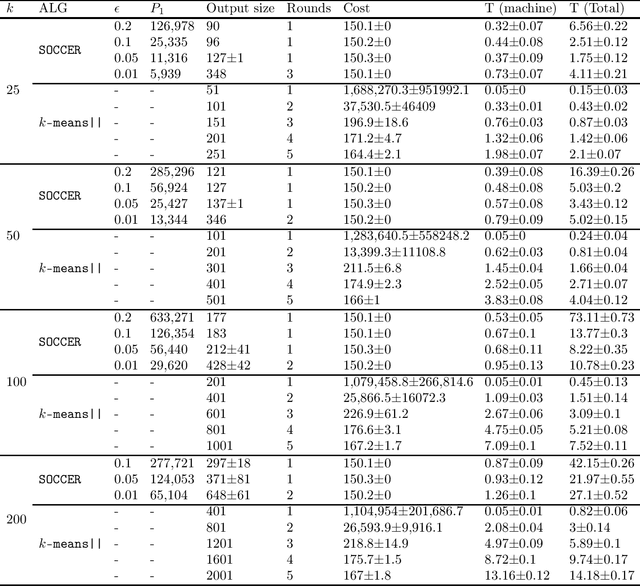
We propose a new algorithm for k-means clustering in a distributed setting, where the data is distributed across many machines, and a coordinator communicates with these machines to calculate the output clustering. Our algorithm guarantees a cost approximation factor and a number of communication rounds that depend only on the computational capacity of the coordinator. Moreover, the algorithm includes a built-in stopping mechanism, which allows it to use fewer communication rounds whenever possible. We show both theoretically and empirically that in many natural cases, indeed 1-4 rounds suffice. In comparison with the popular k-means|| algorithm, our approach allows exploiting a larger coordinator capacity to obtain a smaller number of rounds. Our experiments show that the k-means cost obtained by the proposed algorithm is usually better than the cost obtained by k-means||, even when the latter is allowed a larger number of rounds. Moreover, the machine running time in our approach is considerably smaller than that of k-means||. Code for running the algorithm and experiments is available at https://github.com/selotape/distributed_k_means.