 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Effect of Receptive Field Size in U-Net Models for Medical Image Segmentation
Jun 24, 2024Medical image segmentation is a critical task in healthcare applications, and U-Nets have demonstrated promising results. This work delves into the understudied aspect of receptive field (RF) size and its impact on the U-Net and Attention U-Net architectures. This work explores several critical elements including the relationship between RF size, characteristics of the region of interest, and model performance, as well as the balance between RF size and computational costs for U-Net and Attention U-Net methods for different datasets. This work also proposes a mathematical notation for representing the theoretical receptive field (TRF) of a given layer in a network and proposes two new metrics - effective receptive field (ERF) rate and the Object rate to quantify the fraction of significantly contributing pixels within the ERF against the TRF area and assessing the relative size of the segmentation object compared to the TRF size respectively. The results demonstrate that there exists an optimal TRF size that successfully strikes a balance between capturing a wider global context and maintaining computational efficiency, thereby optimizing model performance. Interestingly, a distinct correlation is observed between the data complexity and the required TRF size; segmentation based solely on contrast achieved peak performance even with smaller TRF sizes, whereas more complex segmentation tasks necessitated larger TRFs. Attention U-Net models consistently outperformed their U-Net counterparts, highlighting the value of attention mechanisms regardless of TRF size. These novel insights present an invaluable resource for developing more efficient U-Net-based architectures for medical imaging and pave the way for future exploration. A tool is also developed that calculates the TRF for a U-Net (and Attention U-Net) model, and also suggest an appropriate TRF size for a given model and dataset.
Multi-Threshold Attention U-Net based Model for Multimodal Brain Tumor Segmentation in MRI scans
Jan 29, 2021



Gliomas are one of the most frequent brain tumors and are classified into high grade and low grade gliomas. The segmentation of various regions such as tumor core, enhancing tumor etc. plays an important role in determining severity and prognosis. Here, we have developed a multi-threshold model based on attention U-Net for identification of various regions of the tumor in magnetic resonance imaging (MRI). We propose a multi-path segmentation and built three separate models for the different regions of interest. The proposed model achieved mean Dice Coefficient of 0.59, 0.72, and 0.61 for enhancing tumor, whole tumor and tumor core respectively on the training dataset. The same model gave mean Dice Coefficient of 0.57, 0.73, and 0.61 on the validation dataset and 0.59, 0.72, and 0.57 on the test dataset.
Image Denoising and Super-Resolution using Residual Learning of Deep Convolutional Network
Sep 21, 2018
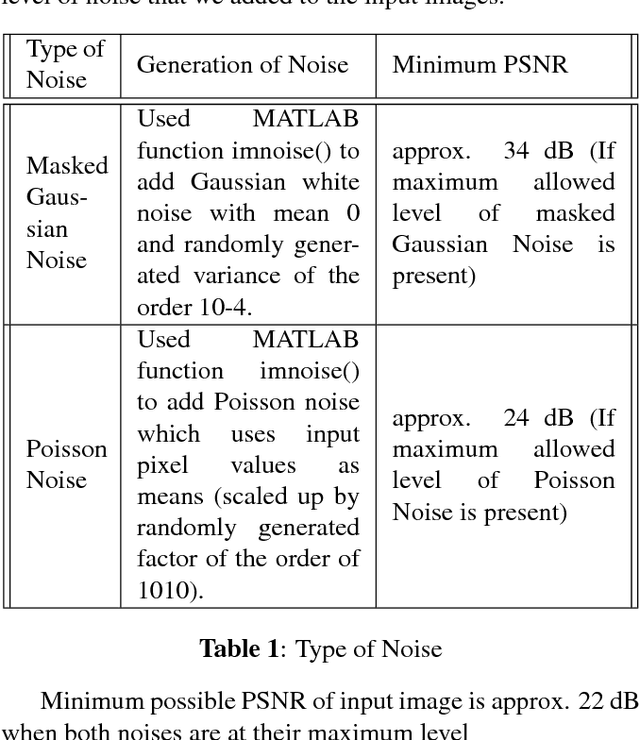
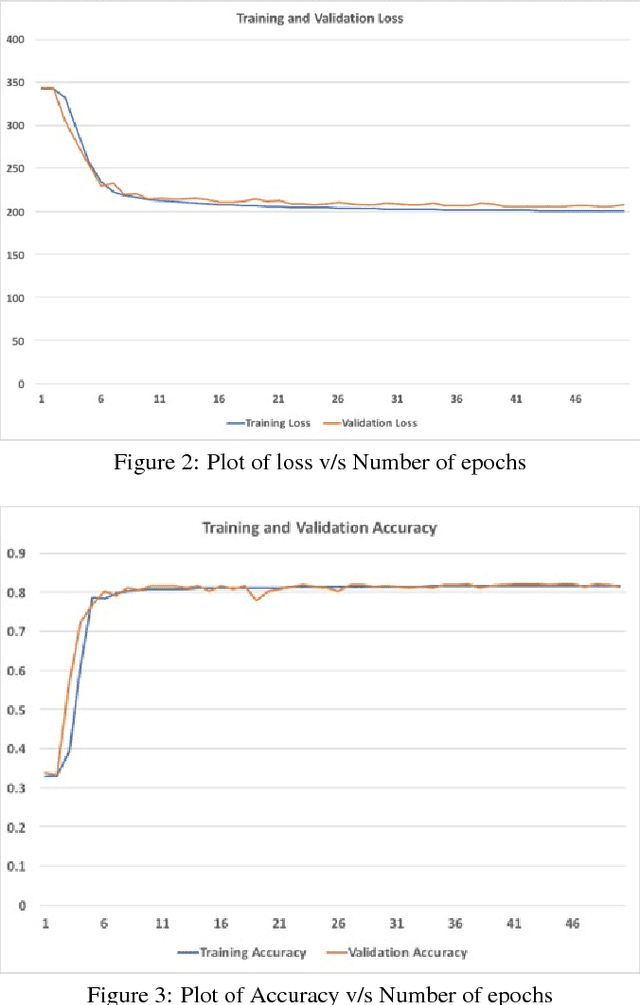
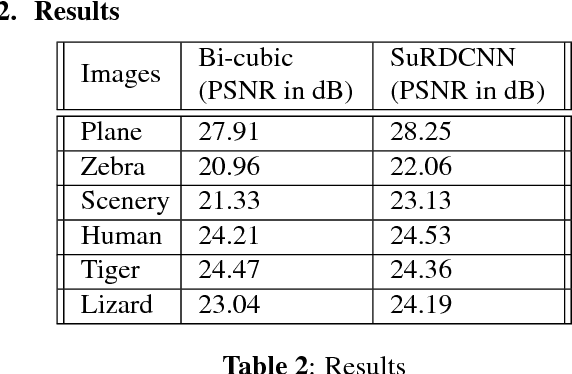
Image super-resolution and denoising are two important tasks in image processing that can lead to improvement in image quality. Image super-resolution is the task of mapping a low resolution image to a high resolution image whereas denoising is the task of learning a clean image from a noisy input. We propose and train a single deep learning network that we term as SuRDCNN (super-resolution and denoising convolutional neural network), to perform these two tasks simultaneously . Our model nearly replicates the architecture of existing state-of-the-art deep learning models for super-resolution and denoising. We use the proven strategy of residual learning, as supported by state-of-the-art networks in this domain. Our trained SuRDCNN is capable of super-resolving image in the presence of Gaussian noise, Poisson noise or any random combination of both of these noises.