 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Dataset and Methodology for Malicious URL Classification
Dec 31, 2024Malicious URL (Uniform Resource Locator) classification is a pivotal aspect of Cybersecurity, offering defense against web-based threats. Despite deep learning's promise in this area, its advancement is hindered by two main challenges: the scarcity of comprehensive, open-source datasets and the limitations of existing models, which either lack real-time capabilities or exhibit suboptimal performance. In order to address these gaps, we introduce a novel, multi-class dataset for malicious URL classification, distinguishing between benign, phishing and malicious URLs, named DeepURLBench. The data has been rigorously cleansed and structured, providing a superior alternative to existing datasets. Notably, the multi-class approach enhances the performance of deep learning models, as compared to a standard binary classification approach. Additionally, we propose improvements to string-based URL classifiers, applying these enhancements to URLNet. Key among these is the integration of DNS-derived features, which enrich the model's capabilities and lead to notable performance gains while preserving real-time runtime efficiency-achieving an effective balance for cybersecurity applications.
Towards Understanding Learning in Neural Networks with Linear Teachers
Jan 07, 2021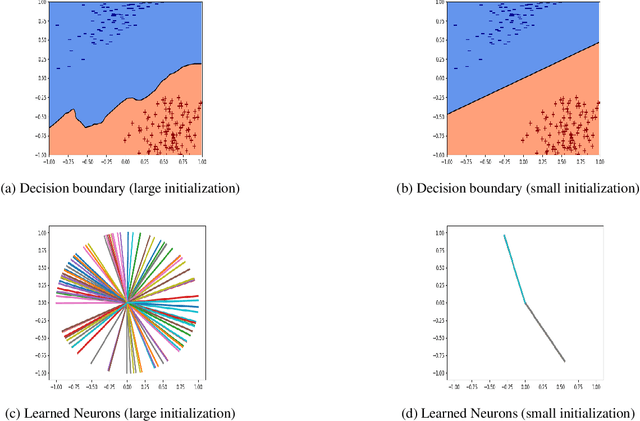
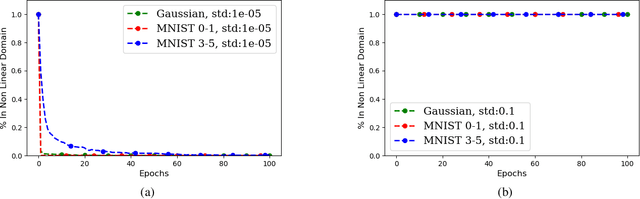
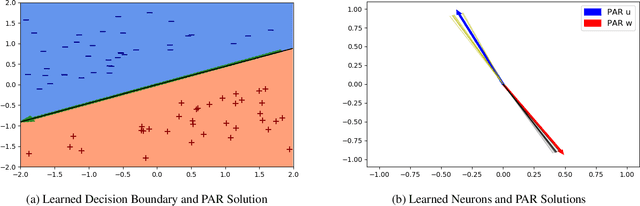
Can a neural network minimizing cross-entropy learn linearly separable data? Despite progress in the theory of deep learning, this question remains unsolved. Here we prove that SGD globally optimizes this learning problem for a two-layer network with Leaky ReLU activations. The learned network can in principle be very complex. However, empirical evidence suggests that it often turns out to be approximately linear. We provide theoretical support for this phenomenon by proving that if network weights converge to two weight clusters, this will imply an approximately linear decision boundary. Finally, we show a condition on the optimization that leads to weight clustering. We provide empirical results that validate our theoretical analysis.