 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Towards an Efficient Semantic Segmentation Method of ID Cards for Verification Systems
Nov 24, 2021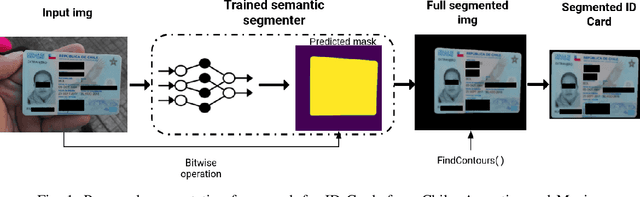

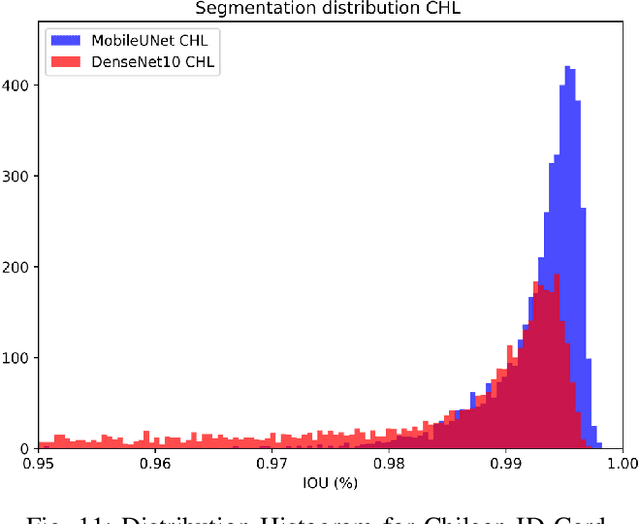
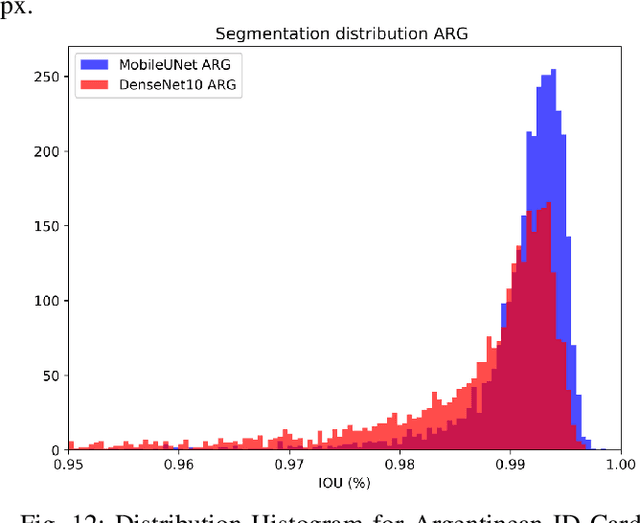
Removing the background in ID Card images is a real challenge for remote verification systems because many of the re-digitalised images present cluttered backgrounds, poor illumination conditions, distortion and occlusions. The background in ID Card images confuses the classifiers and the text extraction. Due to the lack of available images for research, this field represents an open problem in computer vision today. This work proposes a method for removing the background using semantic segmentation of ID Cards. In the end, images captured in the wild from the real operation, using a manually labelled dataset consisting of 45,007 images, with five types of ID Cards from three countries (Chile, Argentina and Mexico), including typical presentation attack scenarios, were used. This method can help to improve the following stages in a regular identity verification or document tampering detection system. Two Deep Learning approaches were explored, based on MobileUNet and DenseNet10. The best results were obtained using MobileUNet, with 6.5 million parameters. A Chilean ID Card's mean Intersection Over Union (IoU) was 0.9926 on a private test dataset of 4,988 images. The best results for the fused multi-country dataset of ID Card images from Chile, Argentina and Mexico reached an IoU of 0.9911. The proposed methods are lightweight enough to be used in real-time operation on mobile devices.
Selfie Periocular Verification using an Efficient Super-Resolution Approach
Feb 16, 2021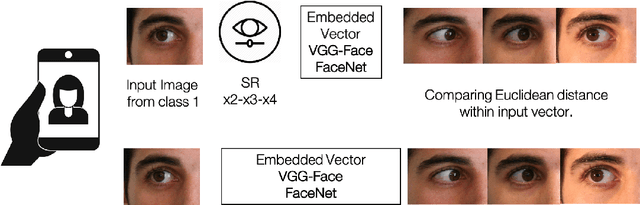
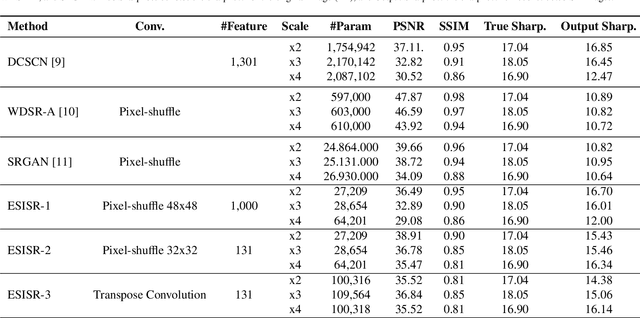
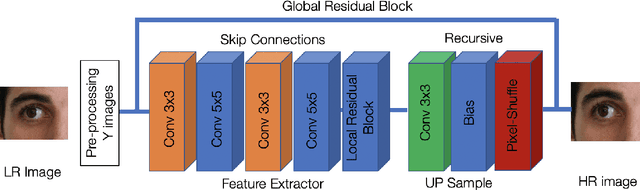
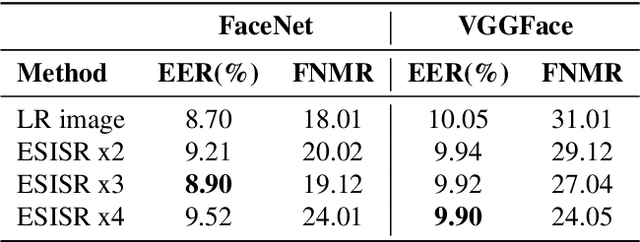
Selfie-based biometrics has great potential for a wide range of applications from marketing to higher security environments like online banking. This is now especially relevant since e.g. periocular verification is contactless, and thereby safe to use in pandemics such as COVID-19. However, selfie-based biometrics faces some challenges since there is limited control over the data acquisition conditions. Therefore, super-resolution has to be used to increase the quality of the captured images. Most of the state of the art super-resolution methods use deep networks with large filters, thereby needing to train and store a correspondingly large number of parameters, and making their use difficult for mobile devices commonly used for selfie-based. In order to achieve an efficient super-resolution method, we propose an Efficient Single Image Super-Resolution (ESISR) algorithm, which takes into account a trade-off between the efficiency of the deep neural network and the size of its filters. To that end, the method implements a novel loss function based on the Sharpness metric. This metric turns out to be more suitable for increasing the quality of the eye images. Our method drastically reduces the number of parameters when compared with Deep CNNs with Skip Connection and Network (DCSCN): from 2,170,142 to 28,654 parameters when the image size is increased by a factor of x3. Furthermore, the proposed method keeps the sharp quality of the images, which is highly relevant for biometric recognition purposes. The results on remote verification systems with raw images reached an Equal Error Rate (EER) of 8.7% for FaceNet and 10.05% for VGGFace. Where embedding vectors were used from periocular images the best results reached an EER of 8.9% (x3) for FaceNet and 9.90% (x4) for VGGFace.