 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Capsules for Object Detection
Apr 11, 2021

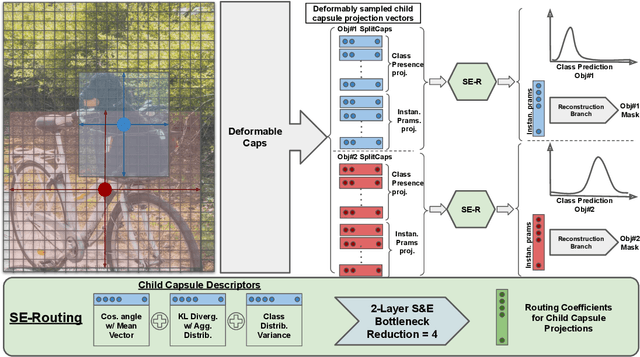

Capsule networks promise significant benefits over convolutional networks by storing stronger internal representations, and routing information based on the agreement between intermediate representations' projections. Despite this, their success has been mostly limited to small-scale classification datasets due to their computationally expensive nature. Recent studies have partially overcome this burden by locally-constraining the dynamic routing of features with convolutional capsules. Though memory efficient, convolutional capsules impose geometric constraints which fundamentally limit the ability of capsules to model the pose/deformation of objects. Further, they do not address the bigger memory concern of class-capsules scaling-up to bigger tasks such as detection or large-scale classification. In this study, we introduce deformable capsules (DeformCaps), a new capsule structure (SplitCaps), and a novel dynamic routing algorithm (SE-Routing) to balance computational efficiency with the need for modeling a large number of objects and classes. We demonstrate that the proposed methods allow capsules to efficiently scale-up to large-scale computer vision tasks for the first time, and create the first-ever capsule network for object detection in the literature. Our proposed architecture is a one-stage detection framework and obtains results on MS COCO which are on-par with state-of-the-art one-stage CNN-based methods, while producing fewer false positive detections.