 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Effective Subnetworks with Gumebel-Softmax
Mar 08, 2022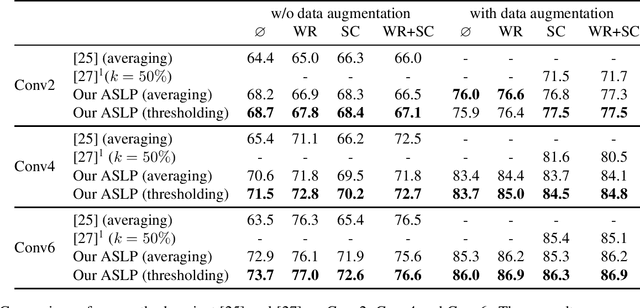
Large and performant neural networks are often overparameterized and can be drastically reduced in size and complexity thanks to pruning. Pruning is a group of methods, which seeks to remove redundant or unnecessary weights or groups of weights in a network. These techniques allow the creation of lightweight networks, which are particularly critical in embedded or mobile applications. In this paper, we devise an alternative pruning method that allows extracting effective subnetworks from larger untrained ones. Our method is stochastic and extracts subnetworks by exploring different topologies which are sampled using Gumbel Softmax. The latter is also used to train probability distributions which measure the relevance of weights in the sampled topologies. The resulting subnetworks are further enhanced using a highly efficient rescaling mechanism that reduces training time and improves performance. Extensive experiments conducted on CIFAR10 show the outperformance of our subnetwork extraction method against the related work.
Weight Reparametrization for Budget-Aware Network Pruning
Jul 27, 2021



Pruning seeks to design lightweight architectures by removing redundant weights in overparameterized networks. Most of the existing techniques first remove structured sub-networks (filters, channels,...) and then fine-tune the resulting networks to maintain a high accuracy. However, removing a whole structure is a strong topological prior and recovering the accuracy, with fine-tuning, is highly cumbersome. In this paper, we introduce an "end-to-end" lightweight network design that achieves training and pruning simultaneously without fine-tuning. The design principle of our method relies on reparametrization that learns not only the weights but also the topological structure of the lightweight sub-network. This reparametrization acts as a prior (or regularizer) that defines pruning masks implicitly from the weights of the underlying network, without increasing the number of training parameters. Sparsity is induced with a budget loss that provides an accurate pruning. Extensive experiments conducted on the CIFAR10 and the TinyImageNet datasets, using standard architectures (namely Conv4, VGG19 and ResNet18), show compelling results without fine-tuning.