 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECWA : Density-Based Clustering using Wasserstein Distance
Oct 25, 2023Clustering is a data analysis method for extracting knowledge by discovering groups of data called clusters. Among these methods, state-of-the-art density-based clustering methods have proven to be effective for arbitrary-shaped clusters. Despite their encouraging results, they suffer to find low-density clusters, near clusters with similar densities, and high-dimensional data. Our proposals are a new characterization of clusters and a new clustering algorithm based on spatial density and probabilistic approach. First of all, sub-clusters are built using spatial density represented as probability density function ($p.d.f$) of pairwise distances between points. A method is then proposed to agglomerate similar sub-clusters by using both their density ($p.d.f$) and their spatial distance. The key idea we propose is to use the Wasserstein metric, a powerful tool to measure the distance between $p.d.f$ of sub-clusters. We show that our approach outperforms other state-of-the-art density-based clustering methods on a wide variety of datasets.
L'explicabilité au service de l'extraction de connaissances : application à des données médicales
Feb 27, 2023


The use of machine learning has increased dramatically in the last decade. The lack of transparency is now a limiting factor, which the field of explainability wants to address. Furthermore, one of the challenges of data mining is to present the statistical relationships of a dataset when they can be highly non-linear. One of the strengths of supervised learning is its ability to find complex statistical relationships that explainability allows to represent in an intelligible way. This paper shows that explanations can be used to extract knowledge from data and shows how feature selection, data subgroup analysis and selection of highly informative instances benefit from explanations. We then present a complete data processing pipeline using these methods on medical data. -- -- L'utilisation de l'apprentissage automatique a connu un bond cette derni\`ere d\'ecennie. Le manque de transparence est aujourd'hui un frein, que le domaine de l'explicabilit\'e veut r\'esoudre. Par ailleurs, un des d\'efis de l'exploration de donn\'ees est de pr\'esenter les relations statistiques d'un jeu de donn\'ees alors que celles-ci peuvent \^etre hautement non-lin\'eaires. Une des forces de l'apprentissage supervis\'e est sa capacit\'e \`a trouver des relations statistiques complexes que l'explicabilit\'e permet de repr\'esenter de mani\`ere intelligible. Ce papier montre que les explications permettent de faire de l'extraction de connaissance sur des donn\'ees et comment la s\'election de variables, l'analyse de sous-groupes de donn\'ees et la s\'election d'instances avec un fort pouvoir informatif b\'en\'eficient des explications. Nous pr\'esentons alors un pipeline complet de traitement des donn\'ees utilisant ces m\'ethodes pour l'exploration de donn\'ees m\'edicales.
Why Should I Choose You? AutoXAI: A Framework for Selecting and Tuning eXplainable AI Solutions
Oct 10, 2022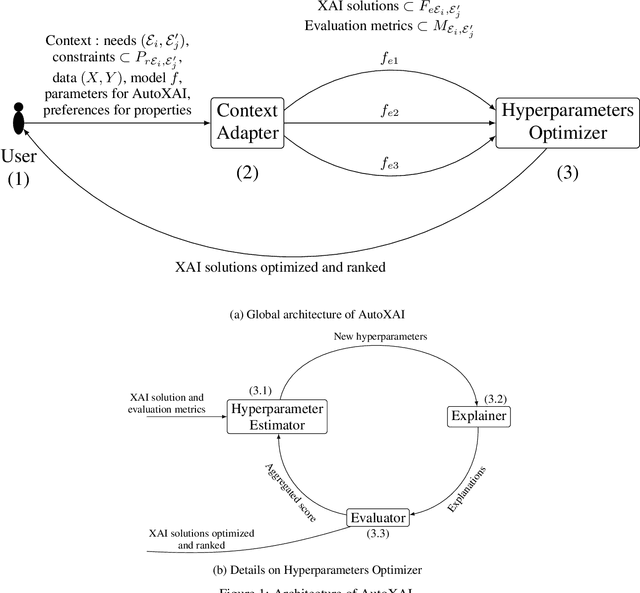

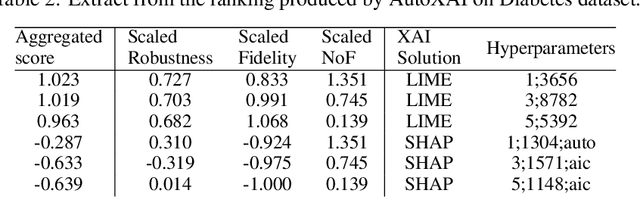
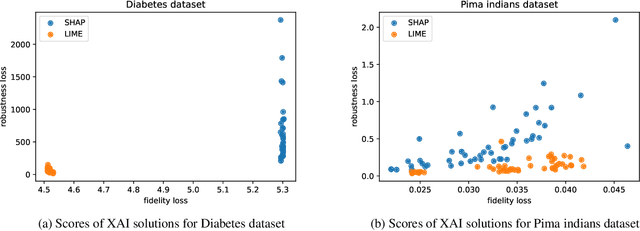
In recent years, a large number of XAI (eXplainable Artificial Intelligence) solutions have been proposed to explain existing ML (Machine Learning) models or to create interpretable ML models. Evaluation measures have recently been proposed and it is now possible to compare these XAI solutions. However, selecting the most relevant XAI solution among all this diversity is still a tedious task, especially when meeting specific needs and constraints. In this paper, we propose AutoXAI, a framework that recommends the best XAI solution and its hyperparameters according to specific XAI evaluation metrics while considering the user's context (dataset, ML model, XAI needs and constraints). It adapts approaches from context-aware recommender systems and strategies of optimization and evaluation from AutoML (Automated Machine Learning). We apply AutoXAI to two use cases, and show that it recommends XAI solutions adapted to the user's needs with the best hyperparameters matching the user's constraints.