 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL'explicabilité au service de l'extraction de connaissances : application à des données médicales
Feb 27, 2023


The use of machine learning has increased dramatically in the last decade. The lack of transparency is now a limiting factor, which the field of explainability wants to address. Furthermore, one of the challenges of data mining is to present the statistical relationships of a dataset when they can be highly non-linear. One of the strengths of supervised learning is its ability to find complex statistical relationships that explainability allows to represent in an intelligible way. This paper shows that explanations can be used to extract knowledge from data and shows how feature selection, data subgroup analysis and selection of highly informative instances benefit from explanations. We then present a complete data processing pipeline using these methods on medical data. -- -- L'utilisation de l'apprentissage automatique a connu un bond cette derni\`ere d\'ecennie. Le manque de transparence est aujourd'hui un frein, que le domaine de l'explicabilit\'e veut r\'esoudre. Par ailleurs, un des d\'efis de l'exploration de donn\'ees est de pr\'esenter les relations statistiques d'un jeu de donn\'ees alors que celles-ci peuvent \^etre hautement non-lin\'eaires. Une des forces de l'apprentissage supervis\'e est sa capacit\'e \`a trouver des relations statistiques complexes que l'explicabilit\'e permet de repr\'esenter de mani\`ere intelligible. Ce papier montre que les explications permettent de faire de l'extraction de connaissance sur des donn\'ees et comment la s\'election de variables, l'analyse de sous-groupes de donn\'ees et la s\'election d'instances avec un fort pouvoir informatif b\'en\'eficient des explications. Nous pr\'esentons alors un pipeline complet de traitement des donn\'ees utilisant ces m\'ethodes pour l'exploration de donn\'ees m\'edicales.
Coalitional strategies for efficient individual prediction explanation
Apr 01, 2021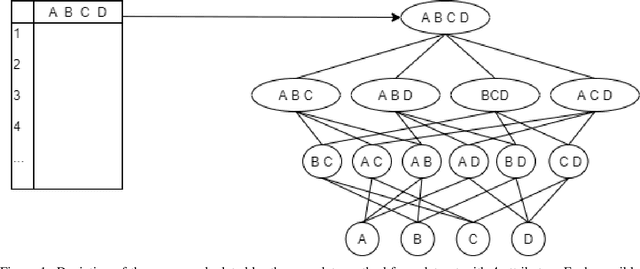
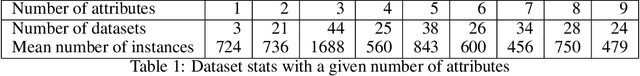

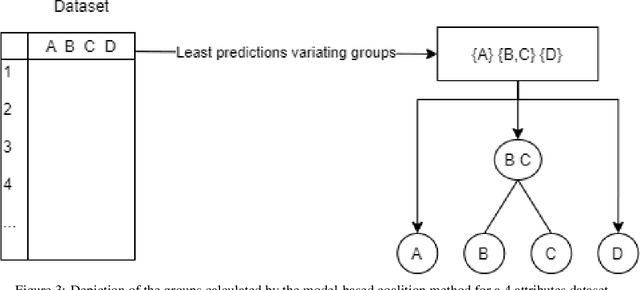
As Machine Learning (ML) is now widely applied in many domains, in both research and industry, an understanding of what is happening inside the black box is becoming a growing demand, especially by non-experts of these models. Several approaches had thus been developed to provide clear insights of a model prediction for a particular observation but at the cost of long computation time or restrictive hypothesis that does not fully take into account interaction between attributes. This paper provides methods based on the detection of relevant groups of attributes -- named coalitions -- influencing a prediction and compares them with the literature. Our results show that these coalitional methods are more efficient than existing ones such as SHapley Additive exPlanation (SHAP). Computation time is shortened while preserving an acceptable accuracy of individual prediction explanations. Therefore, this enables wider practical use of explanation methods to increase trust between developed ML models, end-users, and whoever impacted by any decision where these models played a role.