 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adversarial Robustness of Benjamini Hochberg
Jan 06, 2025The Benjamini-Hochberg (BH) procedure is widely used to control the false detection rate (FDR) in multiple testing. Applications of this control abound in drug discovery, forensics, anomaly detection, and, in particular, machine learning, ranging from nonparametric outlier detection to out-of-distribution detection and one-class classification methods. Considering this control could be relied upon in critical safety/security contexts, we investigate its adversarial robustness. More precisely, we study under what conditions BH does and does not exhibit adversarial robustness, we present a class of simple and easily implementable adversarial test-perturbation algorithms, and we perform computational experiments. With our algorithms, we demonstrate that there are conditions under which BH's control can be significantly broken with relatively few (even just one) test score perturbation(s), and provide non-asymptotic guarantees on the expected adversarial-adjustment to FDR. Our technical analysis involves a combinatorial reframing of the BH procedure as a ``balls into bins'' process, and drawing a connection to generalized ballot problems to facilitate an information-theoretic approach for deriving non-asymptotic lower bounds.
Filtered Poisson Process Bandit on a Continuum
Jul 20, 2020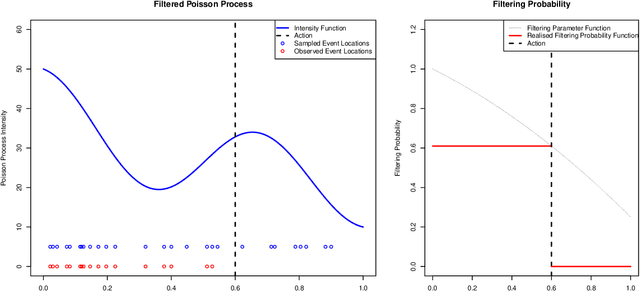
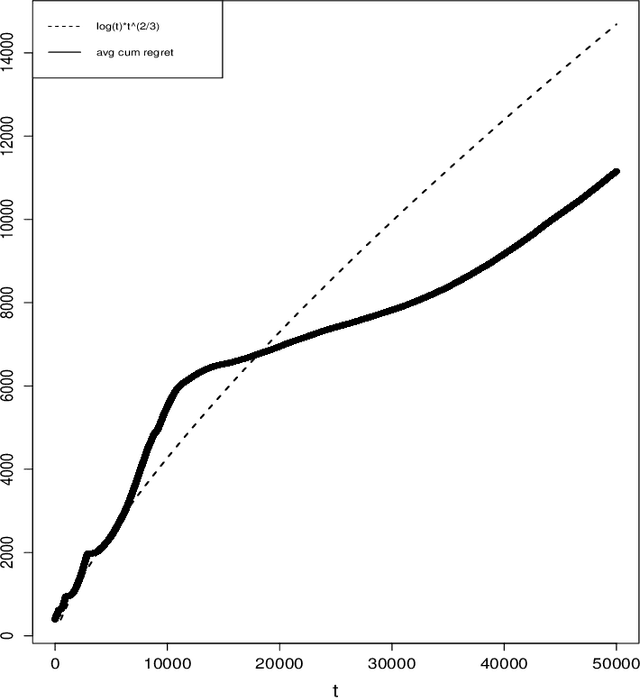
We consider a version of the continuum armed bandit where an action induces a filtered realisation of a non-homogeneous Poisson process. Point data in the filtered sample are then revealed to the decision-maker, whose reward is the total number of revealed points. Using knowledge of the function governing the filtering, but without knowledge of the Poisson intensity function, the decision-maker seeks to maximise the expected number of revealed points over T rounds. We propose an upper confidence bound algorithm for this problem utilising data-adaptive discretisation of the action space. This approach enjoys O(T^(2/3)) regret under a Lipschitz assumption on the reward function. We provide lower bounds on the regret of any algorithm for the problem, via new lower bounds for related finite-armed bandits, and show that the orders of the upper and lower bounds match up to a logarithmic factor.
Combinatorial Multi-Armed Bandits with Filtered Feedback
May 26, 2017Motivated by problems in search and detection we present a solution to a Combinatorial Multi-Armed Bandit (CMAB) problem with both heavy-tailed reward distributions and a new class of feedback, filtered semibandit feedback. In a CMAB problem an agent pulls a combination of arms from a set $\{1,...,k\}$ in each round, generating random outcomes from probability distributions associated with these arms and receiving an overall reward. Under semibandit feedback it is assumed that the random outcomes generated are all observed. Filtered semibandit feedback allows the outcomes that are observed to be sampled from a second distribution conditioned on the initial random outcomes. This feedback mechanism is valuable as it allows CMAB methods to be applied to sequential search and detection problems where combinatorial actions are made, but the true rewards (number of objects of interest appearing in the round) are not observed, rather a filtered reward (the number of objects the searcher successfully finds, which must by definition be less than the number that appear). We present an upper confidence bound type algorithm, Robust-F-CUCB, and associated regret bound of order $\mathcal{O}(\ln(n))$ to balance exploration and exploitation in the face of both filtering of reward and heavy tailed reward distributions.