 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Calibration in Mixup-trained Deep Neural Networks through Confidence-Based Loss Functions
Apr 12, 2020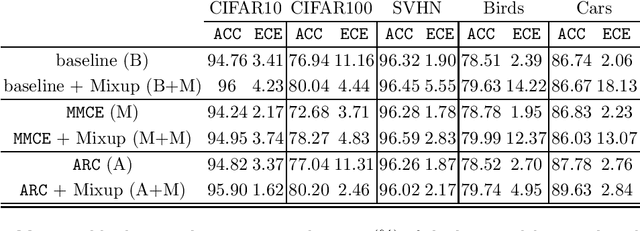
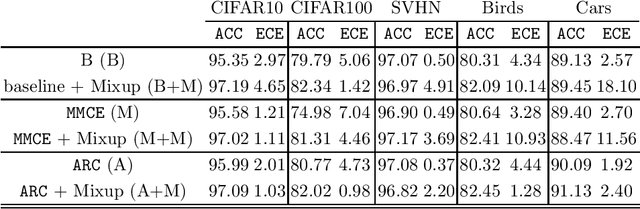
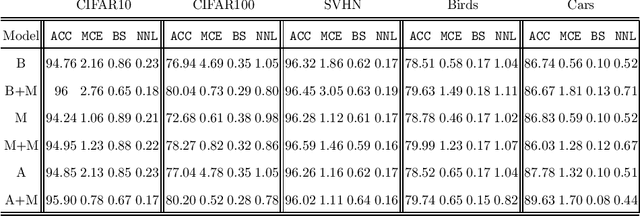
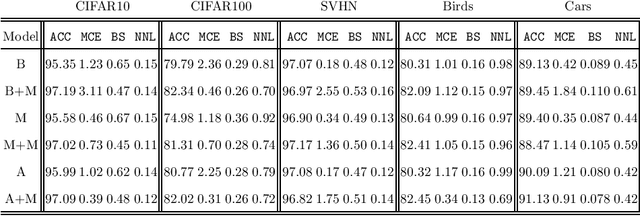
Deep Neural Networks (DNN) represent the state of the art in many tasks. However, due to their overparameterization, their generalization capabilities are in doubt and are still under study. Consequently, DNN can overfit and assign overconfident predictions, as they tend to learn highly oscillating decision thresholds. This has been shown to affect the calibration of the confidences assigned to unseen data. Data Augmentation (DA) strategies have been proposed to overcome some of these limitations. One of the most popular is Mixup, which has shown a great ability to improve the accuracy of these models. Recent work has provided evidence that Mixup also improves the uncertainty quantification and calibration of DNN. In this work, we argue and provide empirical evidence that, due to its fundamentals, Mixup does not necessarily improve calibration. Based on our observations we propose a new loss function that improves the calibration, and also sometimes the accuracy. Our loss is inspired by Bayes decision theory and introduces a new training framework for designing losses for probabilistic modelling. We provide state-of-the-art accuracy with consistent improvements in calibration performance.
Calibration of Deep Probabilistic Models with Decoupled Bayesian Neural Networks
Sep 25, 2019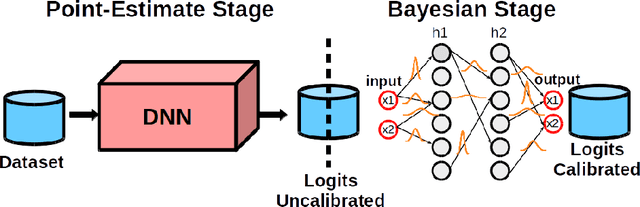
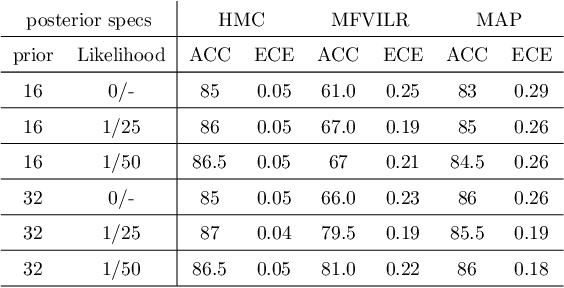
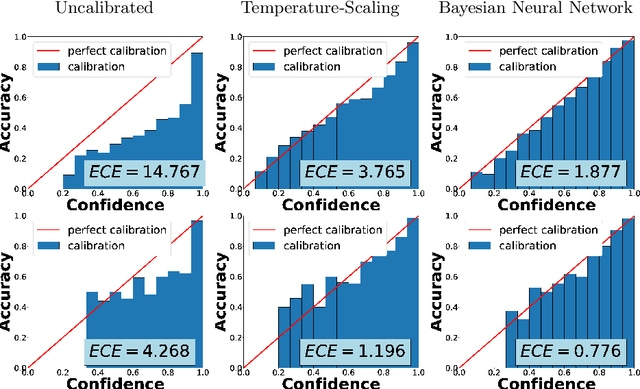
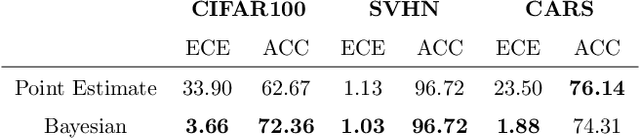
Deep Neural Networks (DNNs) have achieved state-of-the-art accuracy performance in many tasks. However, recent works have pointed out that the outputs provided by these models are not well-calibrated, seriously limiting their use in critical decision scenarios. In this work, we propose to use a decoupled Bayesian stage, implemented with a Bayesian Neural Network (BNN), to map the uncalibrated probabilities provided by a DNN to calibrated ones, consistently improving calibration. Our results evidence that incorporating uncertainty provides more reliable probabilistic models, a critical condition for achieving good calibration. We report a generous collection of experimental results using high-accuracy DNNs in standardized image classification benchmarks, showing the good performance, flexibility and robust behavior of our approach with respect to several state-of-the-art calibration methods. Code for reproducibility is provided.
Generative Models For Deep Learning with Very Scarce Data
Mar 21, 2019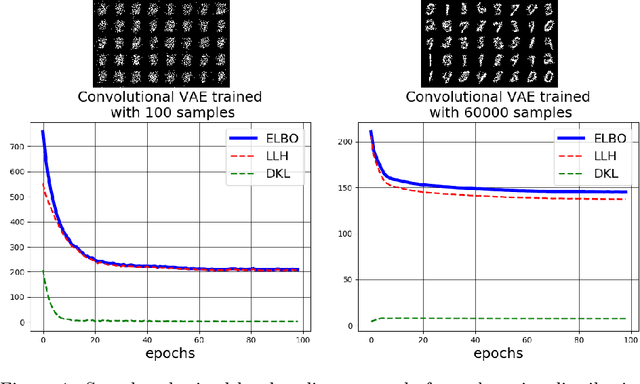



The goal of this paper is to deal with a data scarcity scenario where deep learning techniques use to fail. We compare the use of two well established techniques, Restricted Boltzmann Machines and Variational Auto-encoders, as generative models in order to increase the training set in a classification framework. Essentially, we rely on Markov Chain Monte Carlo (MCMC) algorithms for generating new samples. We show that generalization can be improved comparing this methodology to other state-of-the-art techniques, e.g. semi-supervised learning with ladder networks. Furthermore, we show that RBM is better than VAE generating new samples for training a classifier with good generalization capabilities.
LAYERS: Yet another Neural Network toolkit
Oct 06, 2016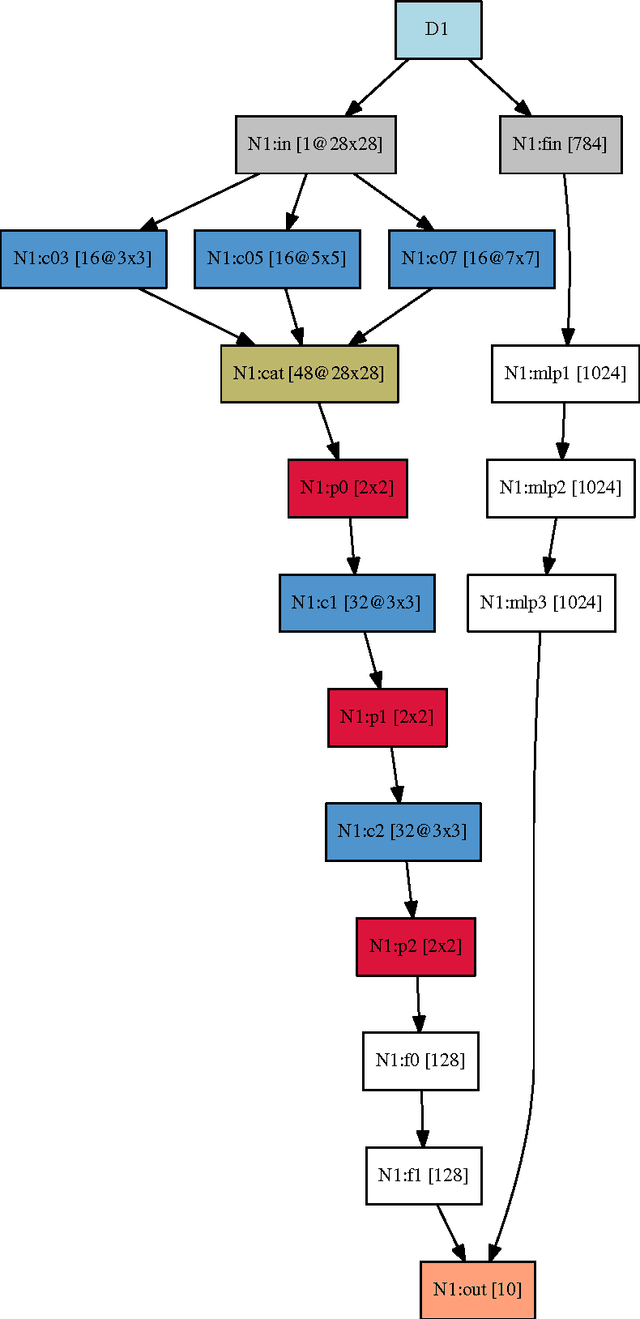
Layers is an open source neural network toolkit aim at providing an easy way to implement modern neural networks. The main user target are students and to this end layers provides an easy scriptting language that can be early adopted. The user has to focus only on design details as network totpology and parameter tunning.