 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Calibration in Mixup-trained Deep Neural Networks through Confidence-Based Loss Functions
Paper and Code
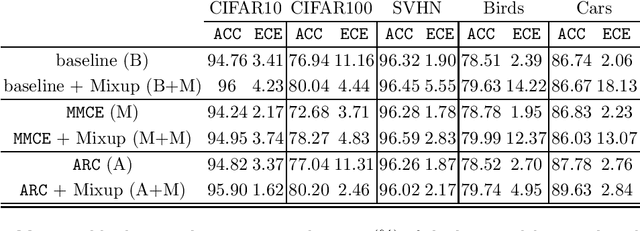
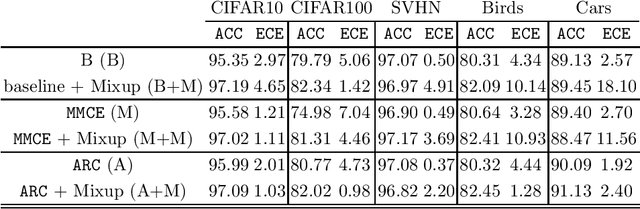
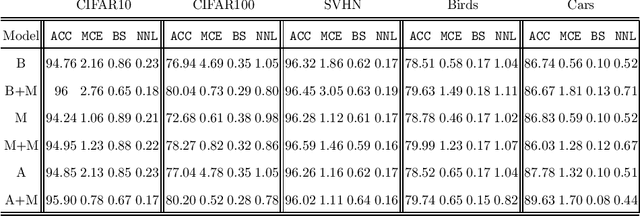
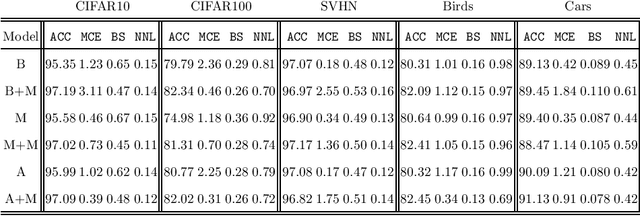
Deep Neural Networks (DNN) represent the state of the art in many tasks. However, due to their overparameterization, their generalization capabilities are in doubt and are still under study. Consequently, DNN can overfit and assign overconfident predictions, as they tend to learn highly oscillating decision thresholds. This has been shown to affect the calibration of the confidences assigned to unseen data. Data Augmentation (DA) strategies have been proposed to overcome some of these limitations. One of the most popular is Mixup, which has shown a great ability to improve the accuracy of these models. Recent work has provided evidence that Mixup also improves the uncertainty quantification and calibration of DNN. In this work, we argue and provide empirical evidence that, due to its fundamentals, Mixup does not necessarily improve calibration. Based on our observations we propose a new loss function that improves the calibration, and also sometimes the accuracy. Our loss is inspired by Bayes decision theory and introduces a new training framework for designing losses for probabilistic modelling. We provide state-of-the-art accuracy with consistent improvements in calibration performance.