 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving latent variable descriptiveness with AutoGen
Jun 12, 2018

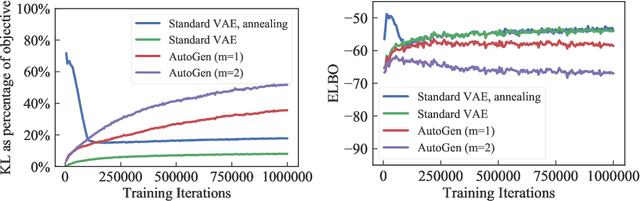

Powerful generative models, particularly in Natural Language Modelling, are commonly trained by maximizing a variational lower bound on the data log likelihood. These models often suffer from poor use of their latent variable, with ad-hoc annealing factors used to encourage retention of information in the latent variable. We discuss an alternative and general approach to latent variable modelling, based on an objective that combines the data log likelihood as well as the likelihood of a perfect reconstruction through an autoencoder. Tying these together ensures by design that the latent variable captures information about the observations, whilst retaining the ability to generate well. Interestingly, though this approach is a priori unrelated to VAEs, the lower bound attained is identical to the standard VAE bound but with the addition of a simple pre-factor; thus, providing a formal interpretation of the commonly used, ad-hoc pre-factors in training VAEs.