 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Entropy-Based Test and Development Framework for Uncertainty Modeling in Level-Set Visualizations
Sep 13, 2024



We present a simple comparative framework for testing and developing uncertainty modeling in uncertain marching cubes implementations. The selection of a model to represent the probability distribution of uncertain values directly influences the memory use, run time, and accuracy of an uncertainty visualization algorithm. We use an entropy calculation directly on ensemble data to establish an expected result and then compare the entropy from various probability models, including uniform, Gaussian, histogram, and quantile models. Our results verify that models matching the distribution of the ensemble indeed match the entropy. We further show that fewer bins in nonparametric histogram models are more effective whereas large numbers of bins in quantile models approach data accuracy.
Photo-Guided Exploration of Volume Data Features
Oct 18, 2017
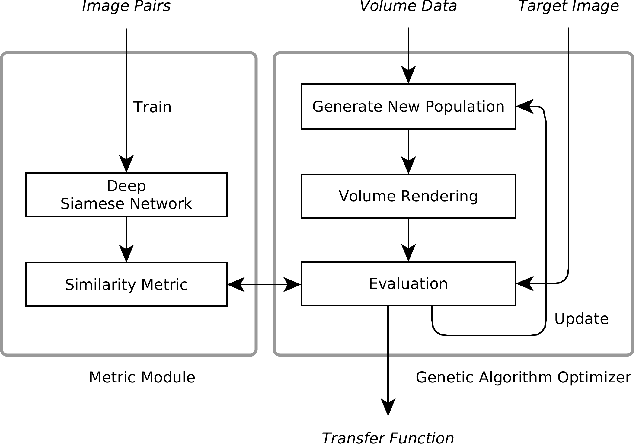
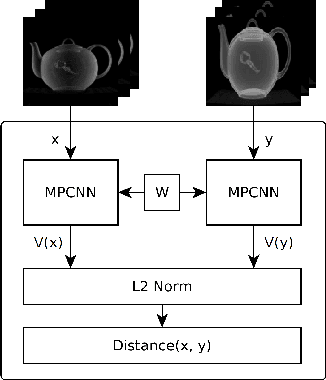
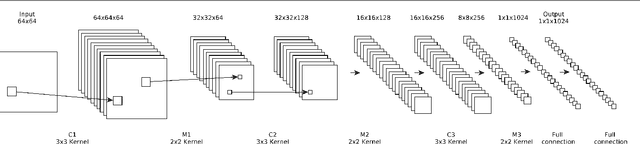
In this work, we pose the question of whether, by considering qualitative information such as a sample target image as input, one can produce a rendered image of scientific data that is similar to the target. The algorithm resulting from our research allows one to ask the question of whether features like those in the target image exists in a given dataset. In that way, our method is one of imagery query or reverse engineering, as opposed to manual parameter tweaking of the full visualization pipeline. For target images, we can use real-world photographs of physical phenomena. Our method leverages deep neural networks and evolutionary optimization. Using a trained similarity function that measures the difference between renderings of a phenomenon and real-world photographs, our method optimizes rendering parameters. We demonstrate the efficacy of our method using a superstorm simulation dataset and images found online. We also discuss a parallel implementation of our method, which was run on NCSA's Blue Waters.