 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Disentanglement of Pose, Appearance and Background from Images and Videos
Jan 26, 2020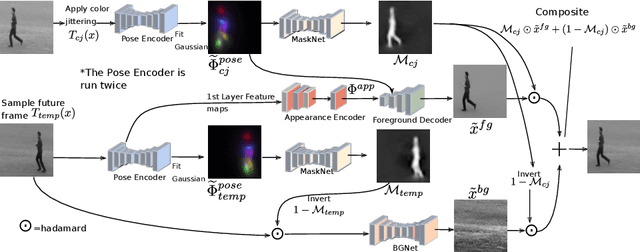

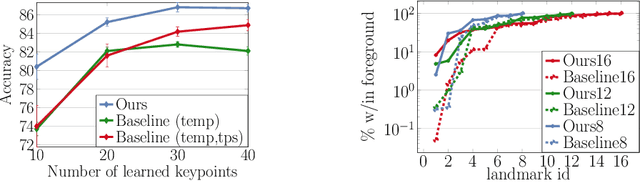
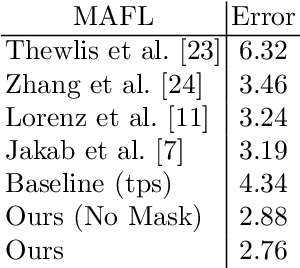
Unsupervised landmark learning is the task of learning semantic keypoint-like representations without the use of expensive input keypoint-level annotations. A popular approach is to factorize an image into a pose and appearance data stream, then to reconstruct the image from the factorized components. The pose representation should capture a set of consistent and tightly localized landmarks in order to facilitate reconstruction of the input image. Ultimately, we wish for our learned landmarks to focus on the foreground object of interest. However, the reconstruction task of the entire image forces the model to allocate landmarks to model the background. This work explores the effects of factorizing the reconstruction task into separate foreground and background reconstructions, conditioning only the foreground reconstruction on the unsupervised landmarks. Our experiments demonstrate that the proposed factorization results in landmarks that are focused on the foreground object of interest. Furthermore, the rendered background quality is also improved, as the background rendering pipeline no longer requires the ill-suited landmarks to model its pose and appearance. We demonstrate this improvement in the context of the video-prediction task.
Video Interpolation and Prediction with Unsupervised Landmarks
Sep 06, 2019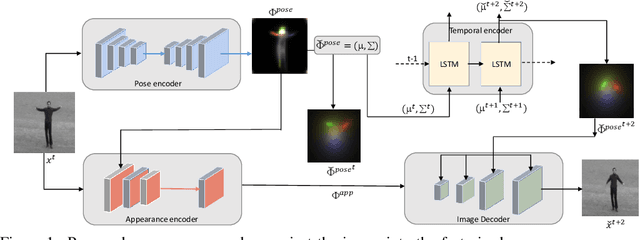
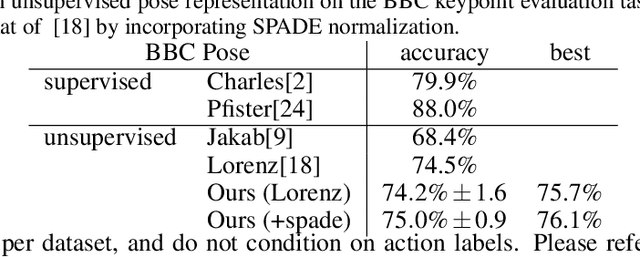
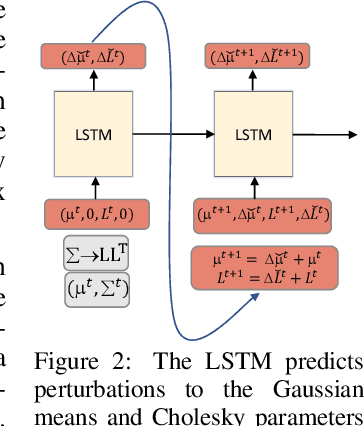
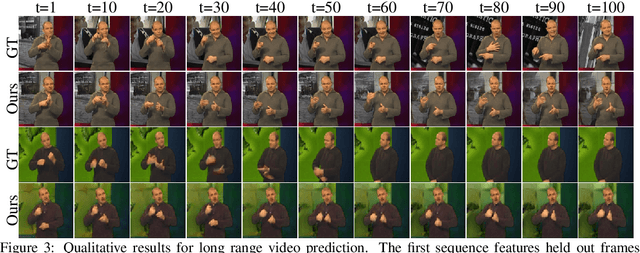
Prediction and interpolation for long-range video data involves the complex task of modeling motion trajectories for each visible object, occlusions and dis-occlusions, as well as appearance changes due to viewpoint and lighting. Optical flow based techniques generalize but are suitable only for short temporal ranges. Many methods opt to project the video frames to a low dimensional latent space, achieving long-range predictions. However, these latent representations are often non-interpretable, and therefore difficult to manipulate. This work poses video prediction and interpolation as unsupervised latent structure inference followed by a temporal prediction in this latent space. The latent representations capture foreground semantics without explicit supervision such as keypoints or poses. Further, as each landmark can be mapped to a coordinate indicating where a semantic part is positioned, we can reliably interpolate within the coordinate domain to achieve predictable motion interpolation. Given an image decoder capable of mapping these landmarks back to the image domain, we are able to achieve high-quality long-range video interpolation and extrapolation by operating on the landmark representation space.