 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDC Cohort Copilot: An AI Copilot for Curating Cohorts from the Genomic Data Commons
Jul 03, 2025Motivation: The Genomic Data Commons (GDC) provides access to high quality, harmonized cancer genomics data through a unified curation and analysis platform centered around patient cohorts. While GDC users can interactively create complex cohorts through the graphical Cohort Builder, users (especially new ones) may struggle to find specific cohort descriptors across hundreds of possible fields and properties. However, users may be better able to describe their desired cohort in free-text natural language. Results: We introduce GDC Cohort Copilot, an open-source copilot tool for curating cohorts from the GDC. GDC Cohort Copilot automatically generates the GDC cohort filter corresponding to a user-input natural language description of their desired cohort, before exporting the cohort back to the GDC for further analysis. An interactive user interface allows users to further refine the generated cohort. We develop and evaluate multiple large language models (LLMs) for GDC Cohort Copilot and demonstrate that our locally-served, open-source GDC Cohort LLM achieves better results than GPT-4o prompting in generating GDC cohorts. Availability and implementation: The standalone docker image for GDC Cohort Copilot is available at https://quay.io/repository/cdis/gdc-cohort-copilot. Source code is available at https://github.com/uc-cdis/gdc-cohort-copilot. GDC Cohort LLM weights are available at https://huggingface.co/uc-ctds.
Multimodal Survival Modeling in the Age of Foundation Models
May 12, 2025



The Cancer Genome Atlas (TCGA) has enabled novel discoveries and served as a large-scale reference through its harmonized genomics, clinical, and image data. Prior studies have trained bespoke cancer survival prediction models from unimodal or multimodal TCGA data. A modern paradigm in biomedical deep learning is the development of foundation models (FMs) to derive meaningful feature embeddings, agnostic to a specific modeling task. Biomedical text especially has seen growing development of FMs. While TCGA contains free-text data as pathology reports, these have been historically underutilized. Here, we investigate the feasibility of training classical, multimodal survival models over zero-shot embeddings extracted by FMs. We show the ease and additive effect of multimodal fusion, outperforming unimodal models. We demonstrate the benefit of including pathology report text and rigorously evaluate the effect of model-based text summarization and hallucination. Overall, we modernize survival modeling by leveraging FMs and information extraction from pathology reports.
LaB-RAG: Label Boosted Retrieval Augmented Generation for Radiology Report Generation
Nov 25, 2024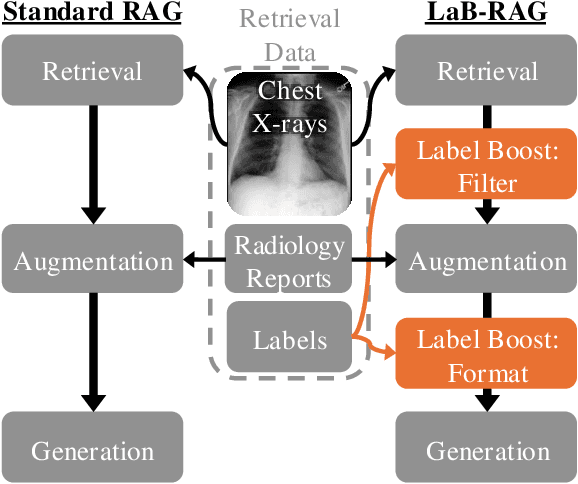
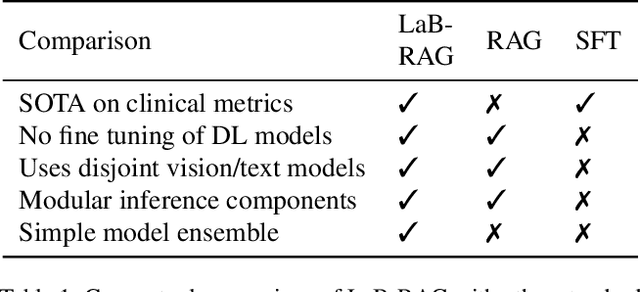
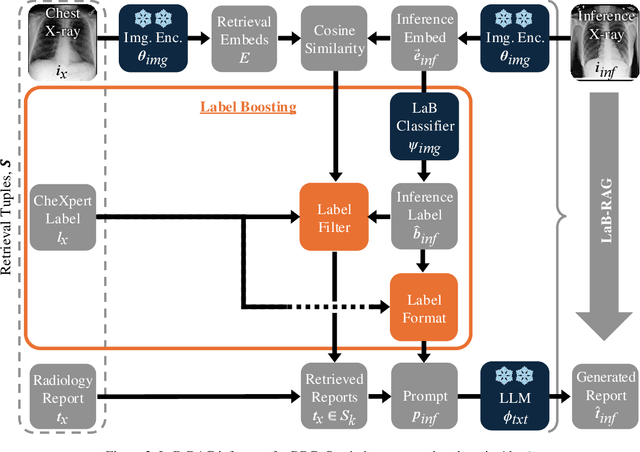

In the current paradigm of image captioning, deep learning models are trained to generate text from image embeddings of latent features. We challenge the assumption that these latent features ought to be high-dimensional vectors which require model fine tuning to handle. Here we propose Label Boosted Retrieval Augmented Generation (LaB-RAG), a text-based approach to image captioning that leverages image descriptors in the form of categorical labels to boost standard retrieval augmented generation (RAG) with pretrained large language models (LLMs). We study our method in the context of radiology report generation (RRG), where the task is to generate a clinician's report detailing their observations from a set of radiological images, such as X-rays. We argue that simple linear classifiers over extracted image embeddings can effectively transform X-rays into text-space as radiology-specific labels. In combination with standard RAG, we show that these derived text labels can be used with general-domain LLMs to generate radiology reports. Without ever training our generative language model or image feature encoder models, and without ever directly "showing" the LLM an X-ray, we demonstrate that LaB-RAG achieves better results across natural language and radiology language metrics compared with other retrieval-based RRG methods, while attaining competitive results compared to other fine-tuned vision-language RRG models. We further present results of our experiments with various components of LaB-RAG to better understand our method. Finally, we critique the use of a popular RRG metric, arguing it is possible to artificially inflate its results without true data-leakage.
An Annotated Glossary for Data Commons, Data Meshes, and Other Data Platforms
Apr 23, 2024Cloud-based data commons, data meshes, data hubs, and other data platforms are important ways to manage, analyze and share data to accelerate research and to support reproducible research. This is an annotated glossary of some of the more common terms used in articles and discussions about these platforms.
Enhancing Instance-Level Image Classification with Set-Level Labels
Nov 17, 2023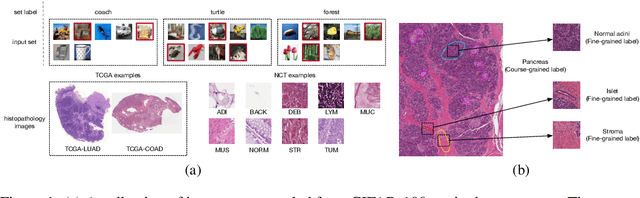

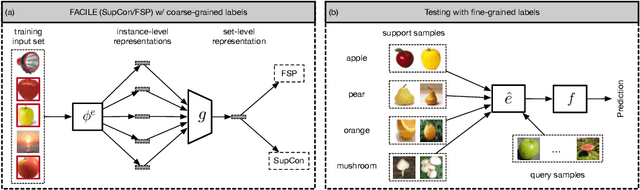
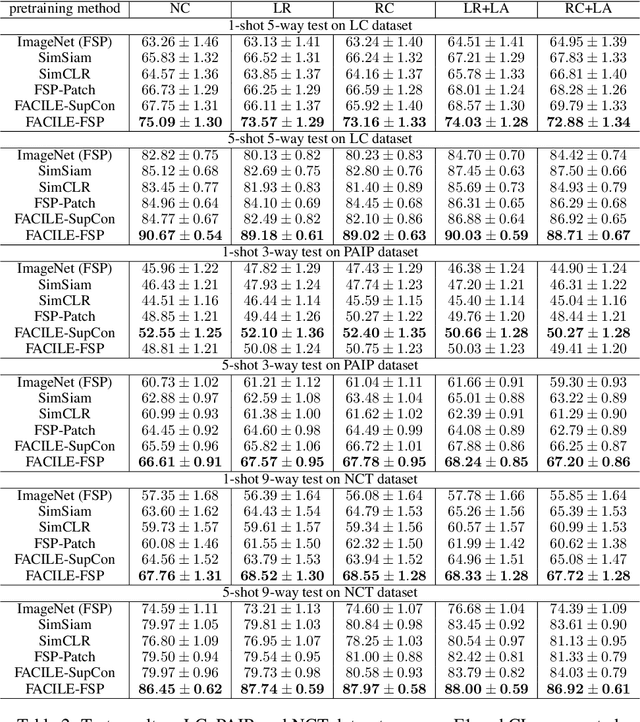
Instance-level image classification tasks have traditionally relied on single-instance labels to train models, e.g., few-shot learning and transfer learning. However, set-level coarse-grained labels that capture relationships among instances can provide richer information in real-world scenarios. In this paper, we present a novel approach to enhance instance-level image classification by leveraging set-level labels. We provide a theoretical analysis of the proposed method, including recognition conditions for fast excess risk rate, shedding light on the theoretical foundations of our approach. We conducted experiments on two distinct categories of datasets: natural image datasets and histopathology image datasets. Our experimental results demonstrate the effectiveness of our approach, showcasing improved classification performance compared to traditional single-instance label-based methods. Notably, our algorithm achieves 13% improvement in classification accuracy compared to the strongest baseline on the histopathology image classification benchmarks. Importantly, our experimental findings align with the theoretical analysis, reinforcing the robustness and reliability of our proposed method. This work bridges the gap between instance-level and set-level image classification, offering a promising avenue for advancing the capabilities of image classification models with set-level coarse-grained labels.
BALanCe: Deep Bayesian Active Learning via Equivalence Class Annealing
Dec 27, 2021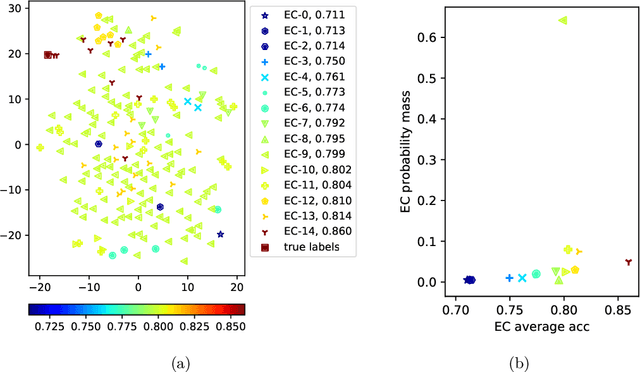


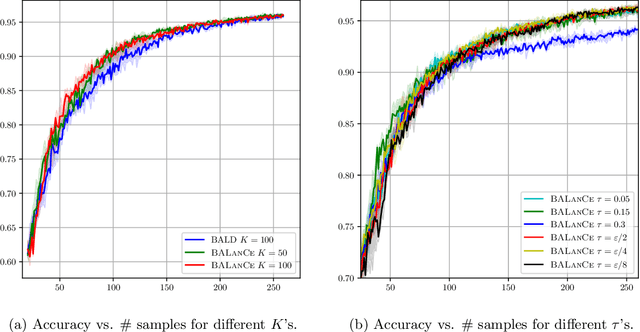
Active learning has demonstrated data efficiency in many fields. Existing active learning algorithms, especially in the context of deep Bayesian active models, rely heavily on the quality of uncertainty estimations of the model. However, such uncertainty estimates could be heavily biased, especially with limited and imbalanced training data. In this paper, we propose BALanCe, a Bayesian deep active learning framework that mitigates the effect of such biases. Concretely, BALanCe employs a novel acquisition function which leverages the structure captured by equivalence hypothesis classes and facilitates differentiation among different equivalence classes. Intuitively, each equivalence class consists of instantiations of deep models with similar predictions, and BALanCe adaptively adjusts the size of the equivalence classes as learning progresses. Besides the fully sequential setting, we further propose Batch-BALanCe -- a generalization of the sequential algorithm to the batched setting -- to efficiently select batches of training examples that are jointly effective for model improvement. We show that Batch-BALanCe achieves state-of-the-art performance on several benchmark datasets for active learning, and that both algorithms can effectively handle realistic challenges that often involve multi-class and imbalanced data.