 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Survival Modeling in the Age of Foundation Models
May 12, 2025The Cancer Genome Atlas (TCGA) has enabled novel discoveries and served as a large-scale reference through its harmonized genomics, clinical, and image data. Prior studies have trained bespoke cancer survival prediction models from unimodal or multimodal TCGA data. A modern paradigm in biomedical deep learning is the development of foundation models (FMs) to derive meaningful feature embeddings, agnostic to a specific modeling task. Biomedical text especially has seen growing development of FMs. While TCGA contains free-text data as pathology reports, these have been historically underutilized. Here, we investigate the feasibility of training classical, multimodal survival models over zero-shot embeddings extracted by FMs. We show the ease and additive effect of multimodal fusion, outperforming unimodal models. We demonstrate the benefit of including pathology report text and rigorously evaluate the effect of model-based text summarization and hallucination. Overall, we modernize survival modeling by leveraging FMs and information extraction from pathology reports.
LaB-RAG: Label Boosted Retrieval Augmented Generation for Radiology Report Generation
Nov 25, 2024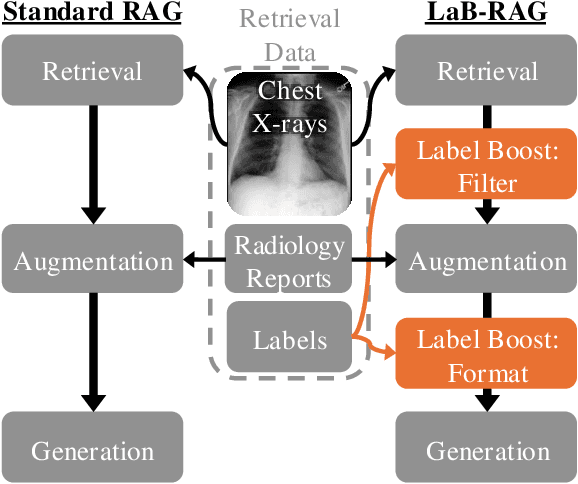
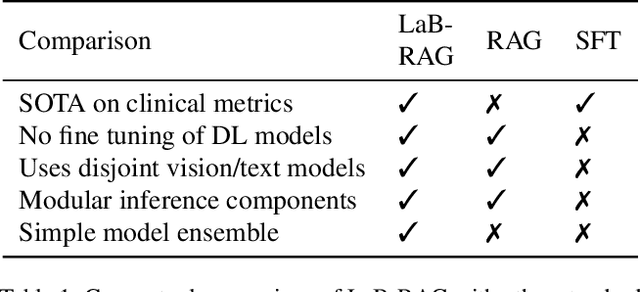
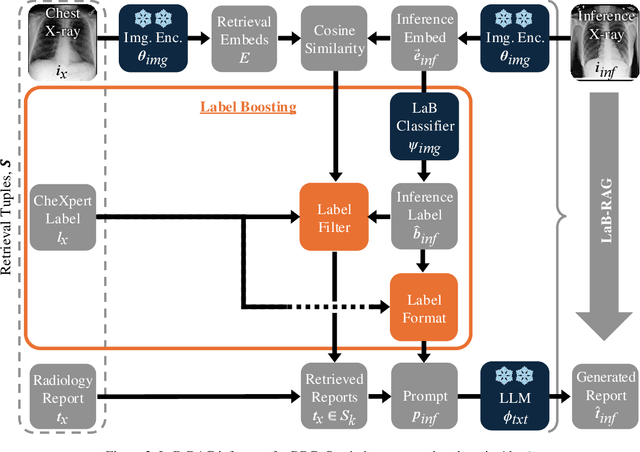

In the current paradigm of image captioning, deep learning models are trained to generate text from image embeddings of latent features. We challenge the assumption that these latent features ought to be high-dimensional vectors which require model fine tuning to handle. Here we propose Label Boosted Retrieval Augmented Generation (LaB-RAG), a text-based approach to image captioning that leverages image descriptors in the form of categorical labels to boost standard retrieval augmented generation (RAG) with pretrained large language models (LLMs). We study our method in the context of radiology report generation (RRG), where the task is to generate a clinician's report detailing their observations from a set of radiological images, such as X-rays. We argue that simple linear classifiers over extracted image embeddings can effectively transform X-rays into text-space as radiology-specific labels. In combination with standard RAG, we show that these derived text labels can be used with general-domain LLMs to generate radiology reports. Without ever training our generative language model or image feature encoder models, and without ever directly "showing" the LLM an X-ray, we demonstrate that LaB-RAG achieves better results across natural language and radiology language metrics compared with other retrieval-based RRG methods, while attaining competitive results compared to other fine-tuned vision-language RRG models. We further present results of our experiments with various components of LaB-RAG to better understand our method. Finally, we critique the use of a popular RRG metric, arguing it is possible to artificially inflate its results without true data-leakage.