 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework for information extraction from tables in biomedical literature
Feb 26, 2019
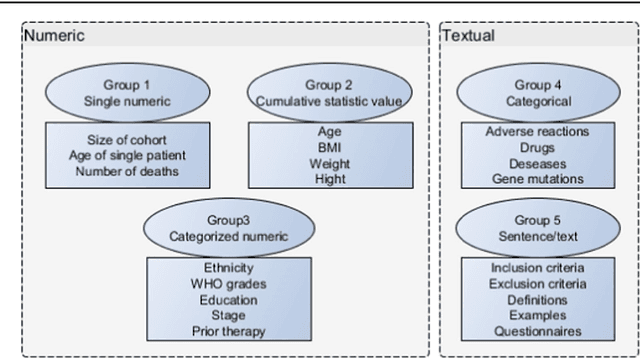
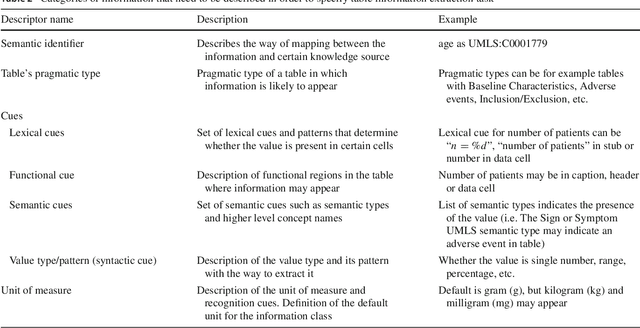

The scientific literature is growing exponentially, and professionals are no more able to cope with the current amount of publications. Text mining provided in the past methods to retrieve and extract information from text; however, most of these approaches ignored tables and figures. The research done in mining table data still does not have an integrated approach for mining that would consider all complexities and challenges of a table. Our research is examining the methods for extracting numerical (number of patients, age, gender distribution) and textual (adverse reactions) information from tables in the clinical literature. We present a requirement analysis template and an integral methodology for information extraction from tables in clinical domain that contains 7 steps: (1) table detection, (2) functional processing, (3) structural processing, (4) semantic tagging, (5) pragmatic processing, (6) cell selection and (7) syntactic processing and extraction. Our approach performed with the F-measure ranged between 82 and 92%, depending on the variable, task and its complexity.
* 24 pages