 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Fuzzy to Formal: Scaling Hospital Quality Improvement with AI
Apr 21, 2026Hospital Quality Improvement (QI) plays a critical role in optimizing healthcare delivery by translating high-level hospital goals into actionable solutions. A critical step of QI is to identify the key modifiable contributing factors, a process we call QI factor discovery, typically through expert-driven semi-structured qualitative tools like fishbone diagrams, chart reviews, and Lean Healthcare methods. AI has the potential to transform and accelerate QI factor discovery, which is traditionally time- and resource-intensive and limited in reproducibility and auditability. Nevertheless, current AI alignment methods assume the task is well-defined, whereas QI factor discovery is an exploratory, fuzzy, and iterative sense-making process that relies on complex implicit expert judgments. To design an AI pipeline that formalizes the QI process while preserving its exploratory components, we propose viewing the task as learning not only LLM prompts but also the overarching natural-language specifications. In particular, we map QI factor discovery to steps of the classical AI/ML development process (problem formalization, model learning, and model validation) where the specifications are tunable hyperparameters. Domain experts and AI agents iteratively refine both the overarching specifications and AI pipeline until AI extractions are concordant with expert annotations and aligned with clinical objectives. We applied this "Human-AI Spec-Solution Co-optimization" framework at an urban safety-net hospital to identify factors driving prolonged length of stay and unplanned 30-day readmissions. The resulting AI-for-QI pipelines achieved $\ge 70\%$ concordance with expert annotations. Compared to prior manual Lean analyses, the AI pipeline was substantially more efficient, recovered previous findings, surfaced new modifiable factors, and produced auditable reasoning traces.
Superhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024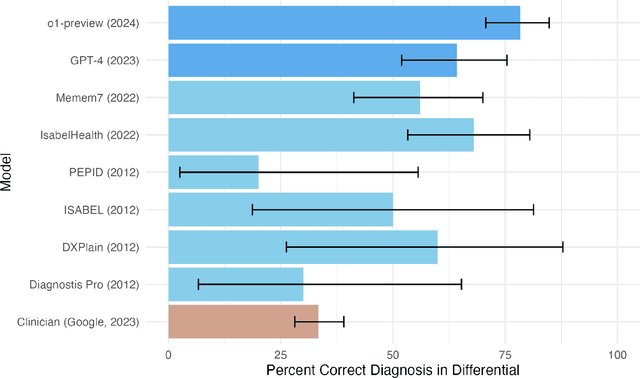
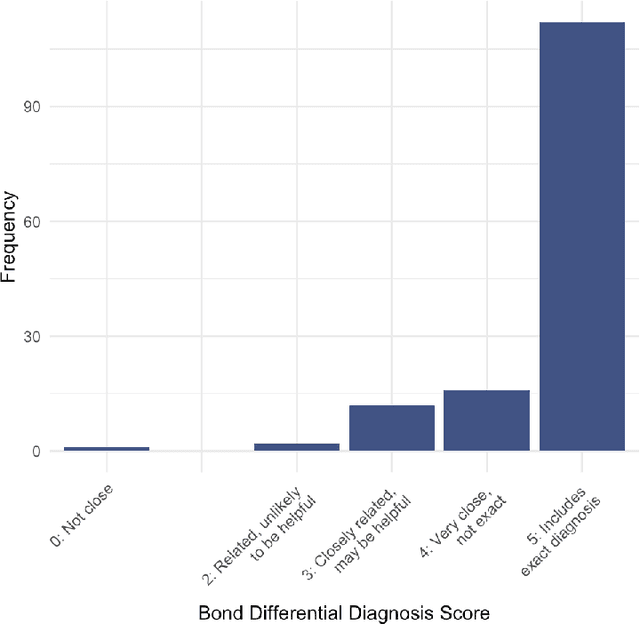

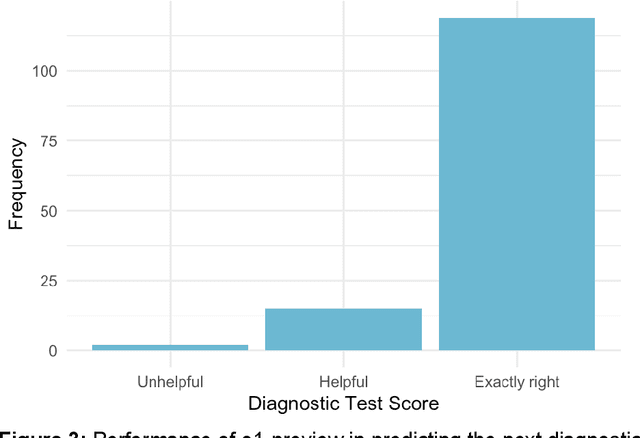
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Methods to Estimate Large Language Model Confidence
Dec 08, 2023



Large Language Models have difficulty communicating uncertainty, which is a significant obstacle to applying LLMs to complex medical tasks. This study evaluates methods to measure LLM confidence when suggesting a diagnosis for challenging clinical vignettes. GPT4 was asked a series of challenging case questions using Chain of Thought and Self Consistency prompting. Multiple methods were investigated to assess model confidence and evaluated on their ability to predict the models observed accuracy. The methods evaluated were Intrinsic Confidence, SC Agreement Frequency and CoT Response Length. SC Agreement Frequency correlated with observed accuracy, yielding a higher Area under the Receiver Operating Characteristic Curve compared to Intrinsic Confidence and CoT Length analysis. SC agreement is the most useful proxy for model confidence, especially for medical diagnosis. Model Intrinsic Confidence and CoT Response Length exhibit a weaker ability to differentiate between correct and incorrect answers, preventing them from being reliable and interpretable markers for model confidence. We conclude GPT4 has a limited ability to assess its own diagnostic accuracy. SC Agreement Frequency is the most useful method to measure GPT4 confidence.
Diagnostic Reasoning Prompts Reveal the Potential for Large Language Model Interpretability in Medicine
Aug 13, 2023One of the major barriers to using large language models (LLMs) in medicine is the perception they use uninterpretable methods to make clinical decisions that are inherently different from the cognitive processes of clinicians. In this manuscript we develop novel diagnostic reasoning prompts to study whether LLMs can perform clinical reasoning to accurately form a diagnosis. We find that GPT4 can be prompted to mimic the common clinical reasoning processes of clinicians without sacrificing diagnostic accuracy. This is significant because an LLM that can use clinical reasoning to provide an interpretable rationale offers physicians a means to evaluate whether LLMs can be trusted for patient care. Novel prompting methods have the potential to expose the black box of LLMs, bringing them one step closer to safe and effective use in medicine.