 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaprobability and Dempster-Shafer in Evidential Reasoning
Mar 27, 2013Evidential reasoning in expert systems has often used ad-hoc uncertainty calculi. Although it is generally accepted that probability theory provides a firm theoretical foundation, researchers have found some problems with its use as a workable uncertainty calculus. Among these problems are representation of ignorance, consistency of probabilistic judgements, and adjustment of a priori judgements with experience. The application of metaprobability theory to evidential reasoning is a new approach to solving these problems. Metaprobability theory can be viewed as a way to provide soft or hard constraints on beliefs in much the same manner as the Dempster-Shafer theory provides constraints on probability masses on subsets of the state space. Thus, we use the Dempster-Shafer theory, an alternative theory of evidential reasoning to illuminate metaprobability theory as a theory of evidential reasoning. The goal of this paper is to compare how metaprobability theory and Dempster-Shafer theory handle the adjustment of beliefs with evidence with respect to a particular thought experiment. Sections 2 and 3 give brief descriptions of the metaprobability and Dempster-Shafer theories. Metaprobability theory deals with higher order probabilities applied to evidential reasoning. Dempster-Shafer theory is a generalization of probability theory which has evolved from a theory of upper and lower probabilities. Section 4 describes a thought experiment and the metaprobability and DempsterShafer analysis of the experiment. The thought experiment focuses on forming beliefs about a population with 6 types of members {1, 2, 3, 4, 5, 6}. A type is uniquely defined by the values of three features: A, B, C. That is, if the three features of one member of the population were known then its type could be ascertained. Each of the three features has two possible values, (e.g. A can be either "a0" or "al"). Beliefs are formed from evidence accrued from two sensors: sensor A, and sensor B. Each sensor senses the corresponding defining feature. Sensor A reports that half of its observations are "a0" and half the observations are 'al'. Sensor B reports that half of its observations are ``b0,' and half are "bl". Based on these two pieces of evidence, what should be the beliefs on the distribution of types in the population? Note that the third feature is not observed by any sensor.
Weighing and Integrating Evidence for Stochastic Simulation in Bayesian Networks
Mar 27, 2013



Stochastic simulation approaches perform probabilistic inference in Bayesian networks by estimating the probability of an event based on the frequency that the event occurs in a set of simulation trials. This paper describes the evidence weighting mechanism, for augmenting the logic sampling stochastic simulation algorithm [Henrion, 1986]. Evidence weighting modifies the logic sampling algorithm by weighting each simulation trial by the likelihood of a network's evidence given the sampled state node values for that trial. We also describe an enhancement to the basic algorithm which uses the evidential integration technique [Chin and Cooper, 1987]. A comparison of the basic evidence weighting mechanism with the Markov blanket algorithm [Pearl, 1987], the logic sampling algorithm, and the evidence integration algorithm is presented. The comparison is aided by analyzing the performance of the algorithms in a simple example network.
Refinement and Coarsening of Bayesian Networks
Mar 27, 2013



In almost all situation assessment problems, it is useful to dynamically contract and expand the states under consideration as assessment proceeds. Contraction is most often used to combine similar events or low probability events together in order to reduce computation. Expansion is most often used to make distinctions of interest which have significant probability in order to improve the quality of the assessment. Although other uncertainty calculi, notably Dempster-Shafer [Shafer, 1976], have addressed these operations, there has not yet been any approach of refining and coarsening state spaces for the Bayesian Network technology. This paper presents two operations for refining and coarsening the state space in Bayesian Networks. We also discuss their practical implications for knowledge acquisition.
An Architecture for Probabilistic Concept-Based Information Retrieval
Mar 27, 2013
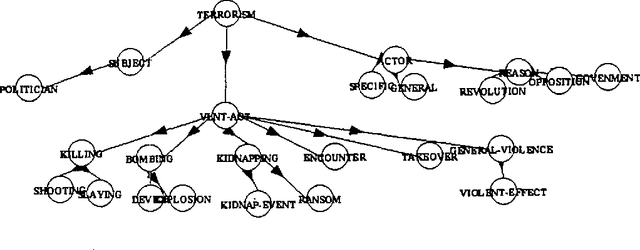


While concept-based methods for information retrieval can provide improved performance over more conventional techniques, they require large amounts of effort to acquire the concepts and their qualitative and quantitative relationships. This paper discusses an architecture for probabilistic concept-based information retrieval which addresses the knowledge acquisition problem. The architecture makes use of the probabilistic networks technology for representing and reasoning about concepts and includes a knowledge acquisition component which partially automates the construction of concept knowledge bases from data. We describe two experiments that apply the architecture to the task of retrieving documents about terrorism from a set of documents from the Reuters news service. The experiments provide positive evidence that the architecture design is feasible and that there are advantages to concept-based methods.
Symbolic Probabilistic Inference with Evidence Potential
Mar 20, 2013

Recent research on the Symbolic Probabilistic Inference (SPI) algorithm[2] has focused attention on the importance of resolving general queries in Bayesian networks. SPI applies the concept of dependency-directed backward search to probabilistic inference, and is incremental with respect to both queries and observations. In response to this research we have extended the evidence potential algorithm [3] with the same features. We call the extension symbolic evidence potential inference (SEPI). SEPI like SPI can handle generic queries and is incremental with respect to queries and observations. While in SPI, operations are done on a search tree constructed from the nodes of the original network, in SEPI, a clique-tree structure obtained from the evidence potential algorithm [3] is the basic framework for recursive query processing. In this paper, we describe the systematic query and caching procedure of SEPI. SEPI begins with finding a clique tree from a Bayesian network-the standard procedure of the evidence potential algorithm. With the clique tree, various probability distributions are computed and stored in each clique. This is the ?pre-processing? step of SEPI. Once this step is done, the query can then be computed. To process a query, a recursive process similar to the SPI algorithm is used. The queries are directed to the root clique and decomposed into queries for the clique's subtrees until a particular query can be answered at the clique at which it is directed. The algorithm and the computation are simple. The SEPI algorithm will be presented in this paper along with several examples.
Symbolic Probabilistic Inference with Continuous Variables
Mar 20, 2013

Research on Symbolic Probabilistic Inference (SPI) [2, 3] has provided an algorithm for resolving general queries in Bayesian networks. SPI applies the concept of dependency directed backward search to probabilistic inference, and is incremental with respect to both queries and observations. Unlike traditional Bayesian network inferencing algorithms, SPI algorithm is goal directed, performing only those calculations that are required to respond to queries. Research to date on SPI applies to Bayesian networks with discrete-valued variables and does not address variables with continuous values. In this papers, we extend the SPI algorithm to handle Bayesian networks made up of continuous variables where the relationships between the variables are restricted to be ?linear gaussian?. We call this variation of the SPI algorithm, SPI Continuous (SPIC). SPIC modifies the three basic SPI operations: multiplication, summation, and substitution. However, SPIC retains the framework of the SPI algorithm, namely building the search tree and recursive query mechanism and therefore retains the goal-directed and incrementality features of SPI.
Backward Simulation in Bayesian Networks
Feb 27, 2013


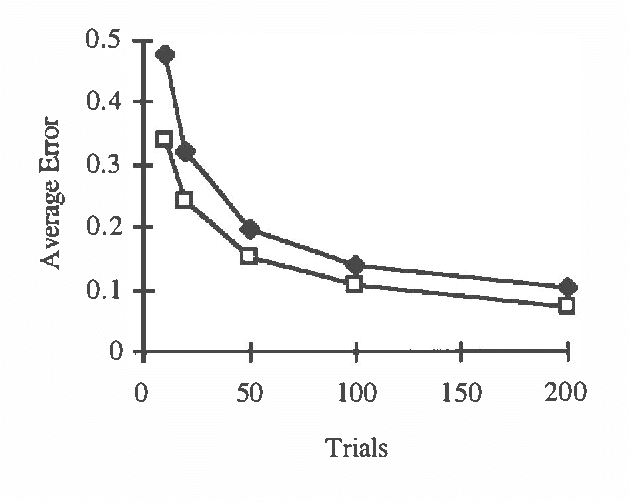
Backward simulation is an approximate inference technique for Bayesian belief networks. It differs from existing simulation methods in that it starts simulation from the known evidence and works backward (i.e., contrary to the direction of the arcs). The technique's focus on the evidence leads to improved convergence in situations where the posterior beliefs are dominated by the evidence rather than by the prior probabilities. Since this class of situations is large, the technique may make practical the application of approximate inference in Bayesian belief networks to many real-world problems.