 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Architecture for Probabilistic Concept-Based Information Retrieval
Paper and Code
Mar 27, 2013
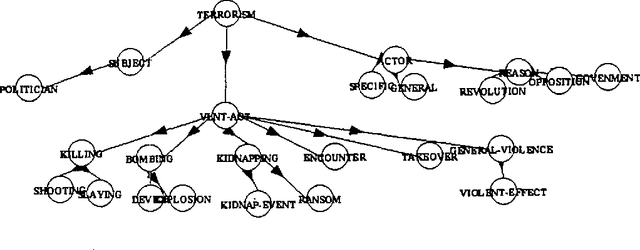


While concept-based methods for information retrieval can provide improved performance over more conventional techniques, they require large amounts of effort to acquire the concepts and their qualitative and quantitative relationships. This paper discusses an architecture for probabilistic concept-based information retrieval which addresses the knowledge acquisition problem. The architecture makes use of the probabilistic networks technology for representing and reasoning about concepts and includes a knowledge acquisition component which partially automates the construction of concept knowledge bases from data. We describe two experiments that apply the architecture to the task of retrieving documents about terrorism from a set of documents from the Reuters news service. The experiments provide positive evidence that the architecture design is feasible and that there are advantages to concept-based methods.