 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurating Grounded Synthetic Data with Global Perspectives for Equitable AI
Jun 18, 2024


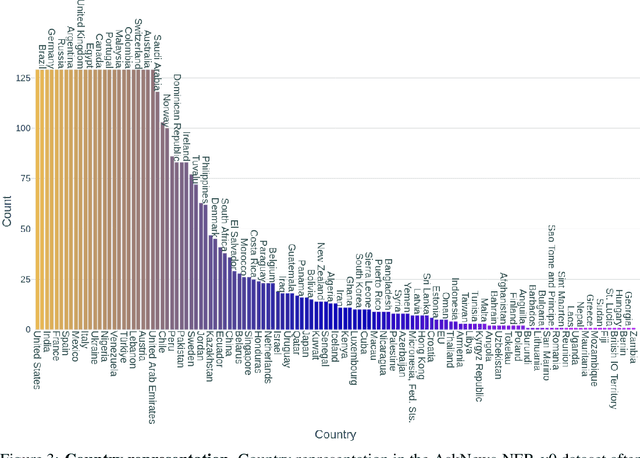
The development of robust AI models relies heavily on the quality and variety of training data available. In fields where data scarcity is prevalent, synthetic data generation offers a vital solution. In this paper, we introduce a novel approach to creating synthetic datasets, grounded in real-world diversity and enriched through strategic diversification. We synthesize data using a comprehensive collection of news articles spanning 12 languages and originating from 125 countries, to ensure a breadth of linguistic and cultural representations. Through enforced topic diversification, translation, and summarization, the resulting dataset accurately mirrors real-world complexities and addresses the issue of underrepresentation in traditional datasets. This methodology, applied initially to Named Entity Recognition (NER), serves as a model for numerous AI disciplines where data diversification is critical for generalizability. Preliminary results demonstrate substantial improvements in performance on traditional NER benchmarks, by up to 7.3%, highlighting the effectiveness of our synthetic data in mimicking the rich, varied nuances of global data sources. This paper outlines the strategies employed for synthesizing diverse datasets and provides such a curated dataset for NER.
High Throughput Training of Deep Surrogates from Large Ensemble Runs
Sep 28, 2023



Recent years have seen a surge in deep learning approaches to accelerate numerical solvers, which provide faithful but computationally intensive simulations of the physical world. These deep surrogates are generally trained in a supervised manner from limited amounts of data slowly generated by the same solver they intend to accelerate. We propose an open-source framework that enables the online training of these models from a large ensemble run of simulations. It leverages multiple levels of parallelism to generate rich datasets. The framework avoids I/O bottlenecks and storage issues by directly streaming the generated data. A training reservoir mitigates the inherent bias of streaming while maximizing GPU throughput. Experiment on training a fully connected network as a surrogate for the heat equation shows the proposed approach enables training on 8TB of data in 2 hours with an accuracy improved by 47% and a batch throughput multiplied by 13 compared to a traditional offline procedure.
Training Deep Surrogate Models with Large Scale Online Learning
Jun 28, 2023



The spatiotemporal resolution of Partial Differential Equations (PDEs) plays important roles in the mathematical description of the world's physical phenomena. In general, scientists and engineers solve PDEs numerically by the use of computationally demanding solvers. Recently, deep learning algorithms have emerged as a viable alternative for obtaining fast solutions for PDEs. Models are usually trained on synthetic data generated by solvers, stored on disk and read back for training. This paper advocates that relying on a traditional static dataset to train these models does not allow the full benefit of the solver to be used as a data generator. It proposes an open source online training framework for deep surrogate models. The framework implements several levels of parallelism focused on simultaneously generating numerical simulations and training deep neural networks. This approach suppresses the I/O and storage bottleneck associated with disk-loaded datasets, and opens the way to training on significantly larger datasets. Experiments compare the offline and online training of four surrogate models, including state-of-the-art architectures. Results indicate that exposing deep surrogate models to more dataset diversity, up to hundreds of GB, can increase model generalization capabilities. Fully connected neural networks, Fourier Neural Operator (FNO), and Message Passing PDE Solver prediction accuracy is improved by 68%, 16% and 7%, respectively.