 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurating Grounded Synthetic Data with Global Perspectives for Equitable AI
Jun 18, 2024


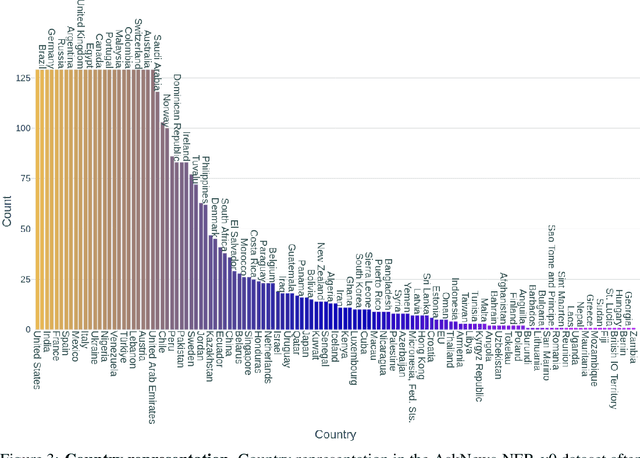
The development of robust AI models relies heavily on the quality and variety of training data available. In fields where data scarcity is prevalent, synthetic data generation offers a vital solution. In this paper, we introduce a novel approach to creating synthetic datasets, grounded in real-world diversity and enriched through strategic diversification. We synthesize data using a comprehensive collection of news articles spanning 12 languages and originating from 125 countries, to ensure a breadth of linguistic and cultural representations. Through enforced topic diversification, translation, and summarization, the resulting dataset accurately mirrors real-world complexities and addresses the issue of underrepresentation in traditional datasets. This methodology, applied initially to Named Entity Recognition (NER), serves as a model for numerous AI disciplines where data diversification is critical for generalizability. Preliminary results demonstrate substantial improvements in performance on traditional NER benchmarks, by up to 7.3%, highlighting the effectiveness of our synthetic data in mimicking the rich, varied nuances of global data sources. This paper outlines the strategies employed for synthesizing diverse datasets and provides such a curated dataset for NER.
Balancing Computational Efficiency and Forecast Error in Machine Learning-based Time-Series Forecasting: Insights from Live Experiments on Meteorological Nowcasting
Sep 26, 2023Machine learning for time-series forecasting remains a key area of research. Despite successful application of many machine learning techniques, relating computational efficiency to forecast error remains an under-explored domain. This paper addresses this topic through a series of real-time experiments to quantify the relationship between computational cost and forecast error using meteorological nowcasting as an example use-case. We employ a variety of popular regression techniques (XGBoost, FC-MLP, Transformer, and LSTM) for multi-horizon, short-term forecasting of three variables (temperature, wind speed, and cloud cover) for multiple locations. During a 5-day live experiment, 4000 data sources were streamed for training and inferencing 144 models per hour. These models were parameterized to explore forecast error for two computational cost minimization methods: a novel auto-adaptive data reduction technique (Variance Horizon) and a performance-based concept drift-detection mechanism. Forecast error of all model variations were benchmarked in real-time against a state-of-the-art numerical weather prediction model. Performance was assessed using classical and novel evaluation metrics. Results indicate that using the Variance Horizon reduced computational usage by more than 50\%, while increasing between 0-15\% in error. Meanwhile, performance-based retraining reduced computational usage by up to 90\% while \emph{also} improving forecast error by up to 10\%. Finally, the combination of both the Variance Horizon and performance-based retraining outperformed other model configurations by up to 99.7\% when considering error normalized to computational usage.