 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Reinforcement Learning: Learn how to play Atari games in 21 minutes
Apr 09, 2018
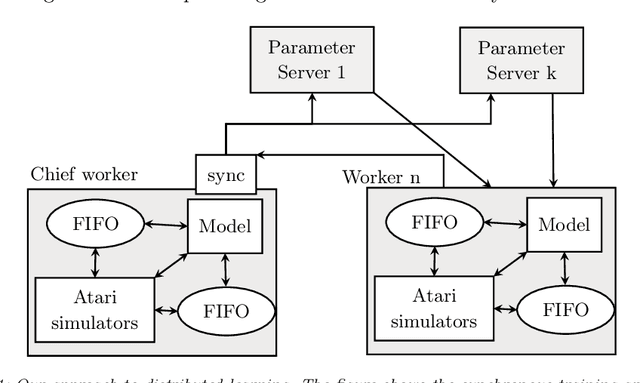
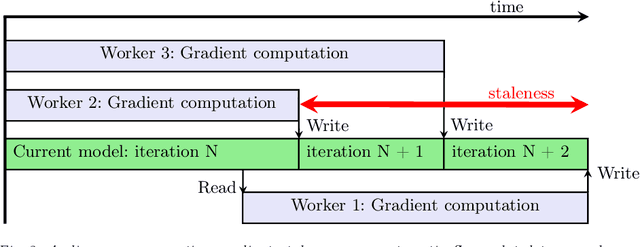
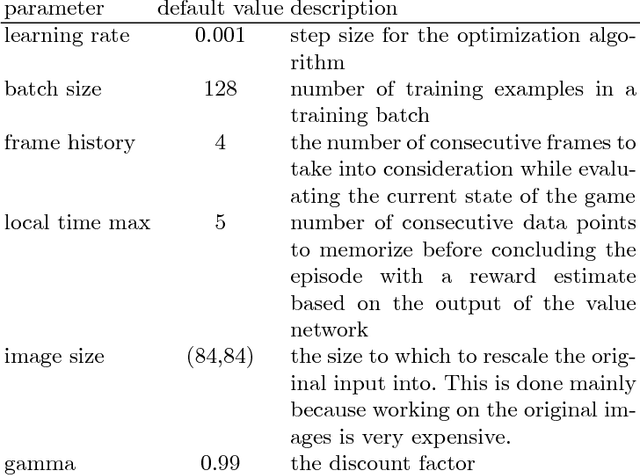
We present a study in Distributed Deep Reinforcement Learning (DDRL) focused on scalability of a state-of-the-art Deep Reinforcement Learning algorithm known as Batch Asynchronous Advantage ActorCritic (BA3C). We show that using the Adam optimization algorithm with a batch size of up to 2048 is a viable choice for carrying out large scale machine learning computations. This, combined with careful reexamination of the optimizer's hyperparameters, using synchronous training on the node level (while keeping the local, single node part of the algorithm asynchronous) and minimizing the memory footprint of the model, allowed us to achieve linear scaling for up to 64 CPU nodes. This corresponds to a training time of 21 minutes on 768 CPU cores, as opposed to 10 hours when using a single node with 24 cores achieved by a baseline single-node implementation.
Atari games and Intel processors
May 19, 2017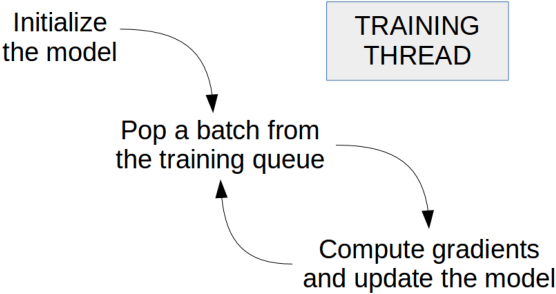
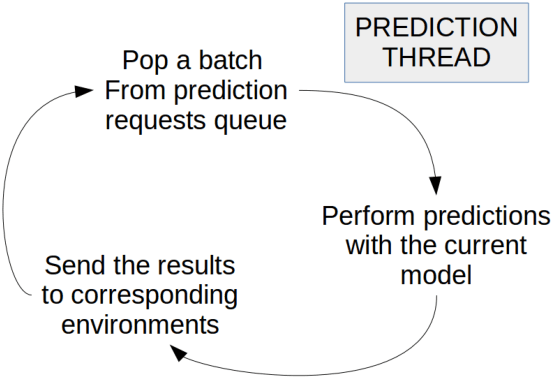
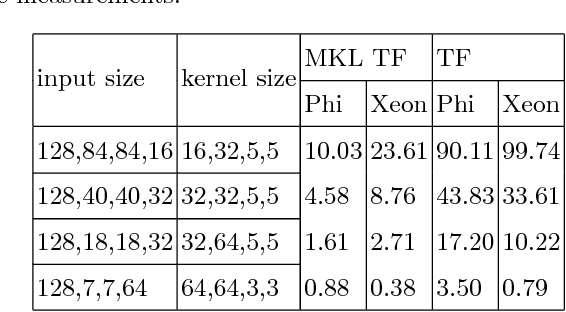
The asynchronous nature of the state-of-the-art reinforcement learning algorithms such as the Asynchronous Advantage Actor-Critic algorithm, makes them exceptionally suitable for CPU computations. However, given the fact that deep reinforcement learning often deals with interpreting visual information, a large part of the train and inference time is spent performing convolutions. In this work we present our results on learning strategies in Atari games using a Convolutional Neural Network, the Math Kernel Library and TensorFlow 0.11rc0 machine learning framework. We also analyze effects of asynchronous computations on the convergence of reinforcement learning algorithms.