Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtari games and Intel processors
Paper and Code
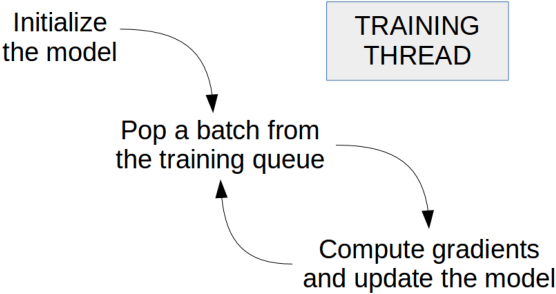
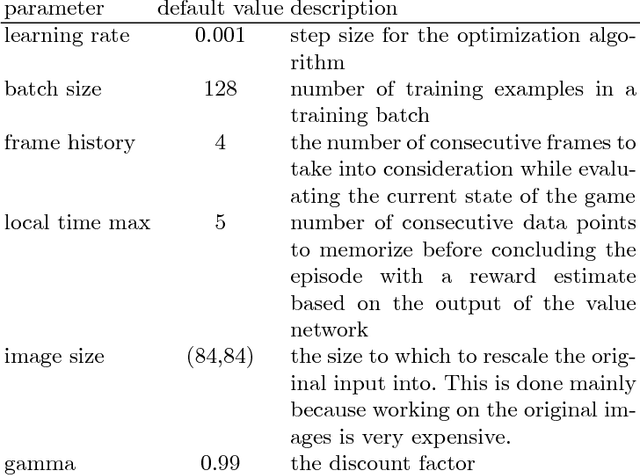
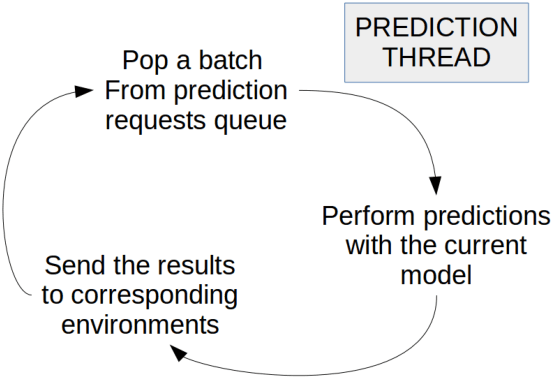
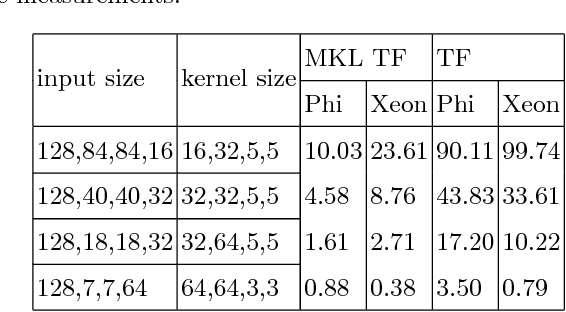
The asynchronous nature of the state-of-the-art reinforcement learning algorithms such as the Asynchronous Advantage Actor-Critic algorithm, makes them exceptionally suitable for CPU computations. However, given the fact that deep reinforcement learning often deals with interpreting visual information, a large part of the train and inference time is spent performing convolutions. In this work we present our results on learning strategies in Atari games using a Convolutional Neural Network, the Math Kernel Library and TensorFlow 0.11rc0 machine learning framework. We also analyze effects of asynchronous computations on the convergence of reinforcement learning algorithms.
View paper on