Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Data Analysis for Word Sense Disambiguation
Mar 01, 2022

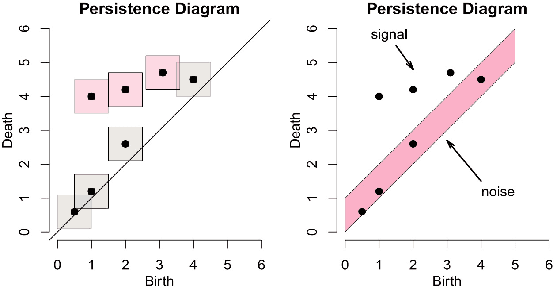
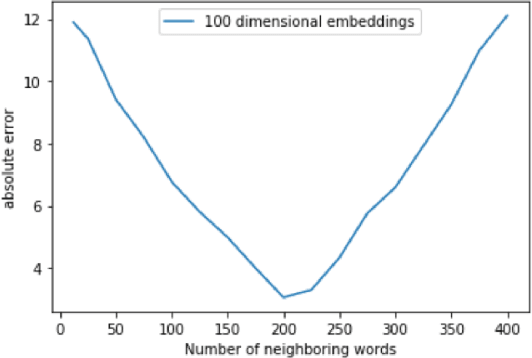
We develop and test a novel unsupervised algorithm for word sense induction and disambiguation which uses topological data analysis. Typical approaches to the problem involve clustering, based on simple low level features of distance in word embeddings. Our approach relies on advanced mathematical concepts in the field of topology which provides a richer conceptualization of clusters for the word sense induction tasks. We use a persistent homology barcode algorithm on the SemCor dataset and demonstrate that our approach gives low relative error on word sense induction. This shows the promise of topological algorithms for natural language processing and we advocate for future work in this promising area.
Via