 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation on Learning, Polluting, and Unlearning the Spam Emails for Lifelong Learning
Dec 24, 2021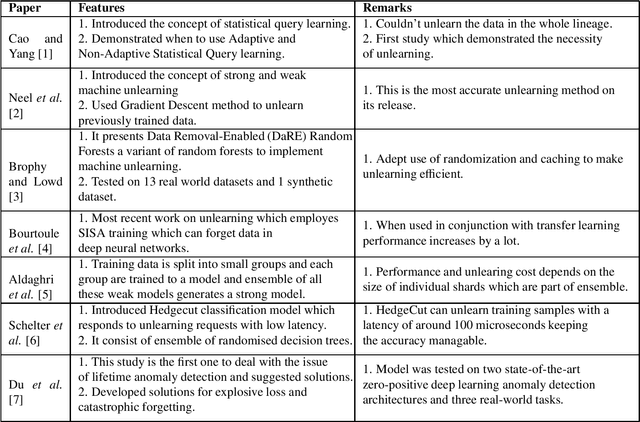
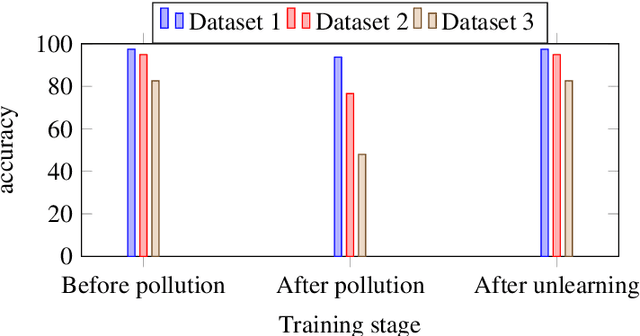
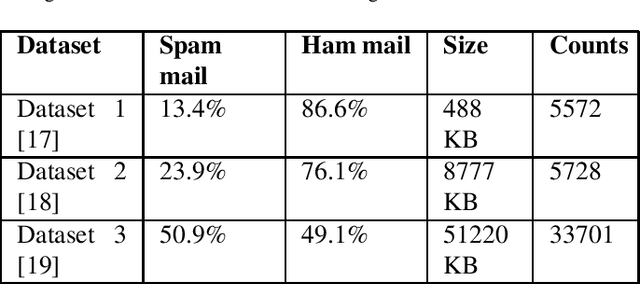
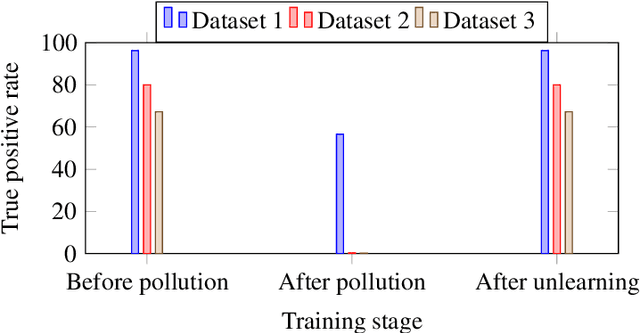
Machine unlearning for security is studied in this context. Several spam email detection methods exist, each of which employs a different algorithm to detect undesired spam emails. But these models are vulnerable to attacks. Many attackers exploit the model by polluting the data, which are trained to the model in various ways. So to act deftly in such situations model needs to readily unlearn the polluted data without the need for retraining. Retraining is impractical in most cases as there is already a massive amount of data trained to the model in the past, which needs to be trained again just for removing a small amount of polluted data, which is often significantly less than 1%. This problem can be solved by developing unlearning frameworks for all spam detection models. In this research, unlearning module is integrated into spam detection models that are based on Naive Bayes, Decision trees, and Random Forests algorithms. To assess the benefits of unlearning over retraining, three spam detection models are polluted and exploited by taking attackers' positions and proving models' vulnerability. Reduction in accuracy and true positive rates are shown in each case showing the effect of pollution on models. Then unlearning modules are integrated into the models, and polluted data is unlearned; on testing the models after unlearning, restoration of performance is seen. Also, unlearning and retraining times are compared with different pollution data sizes on all models. On analyzing the findings, it can be concluded that unlearning is considerably superior to retraining. Results show that unlearning is fast, easy to implement, easy to use, and effective.
Graph Neural Networks: Methods, Applications, and Opportunities
Sep 08, 2021
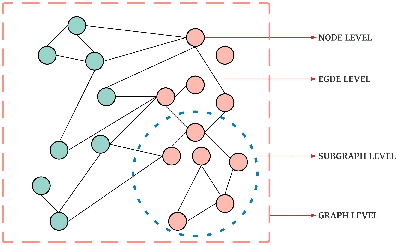
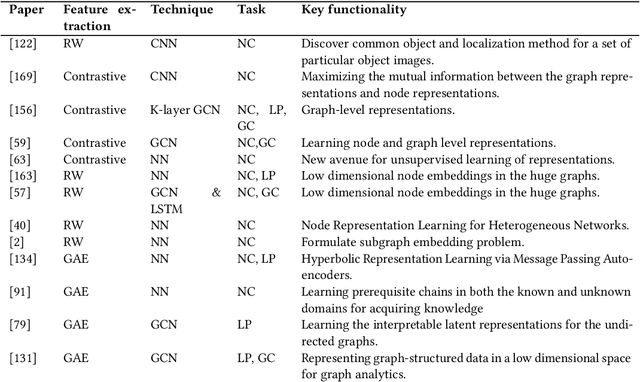
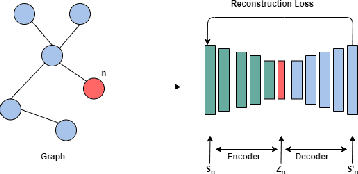
In the last decade or so, we have witnessed deep learning reinvigorating the machine learning field. It has solved many problems in the domains of computer vision, speech recognition, natural language processing, and various other tasks with state-of-the-art performance. The data is generally represented in the Euclidean space in these domains. Various other domains conform to non-Euclidean space, for which graph is an ideal representation. Graphs are suitable for representing the dependencies and interrelationships between various entities. Traditionally, handcrafted features for graphs are incapable of providing the necessary inference for various tasks from this complex data representation. Recently, there is an emergence of employing various advances in deep learning to graph data-based tasks. This article provides a comprehensive survey of graph neural networks (GNNs) in each learning setting: supervised, unsupervised, semi-supervised, and self-supervised learning. Taxonomy of each graph based learning setting is provided with logical divisions of methods falling in the given learning setting. The approaches for each learning task are analyzed from both theoretical as well as empirical standpoints. Further, we provide general architecture guidelines for building GNNs. Various applications and benchmark datasets are also provided, along with open challenges still plaguing the general applicability of GNNs.
A Review on Edge Analytics: Issues, Challenges, Opportunities, Promises, Future Directions, and Applications
Jul 01, 2021
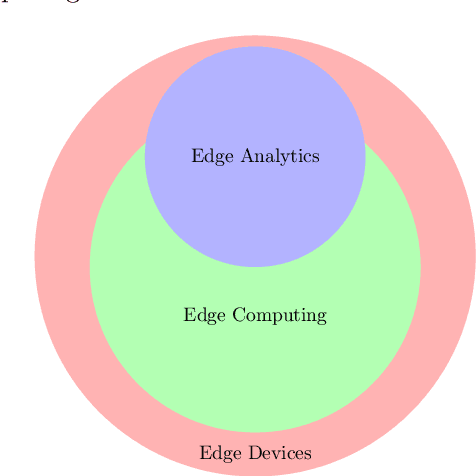
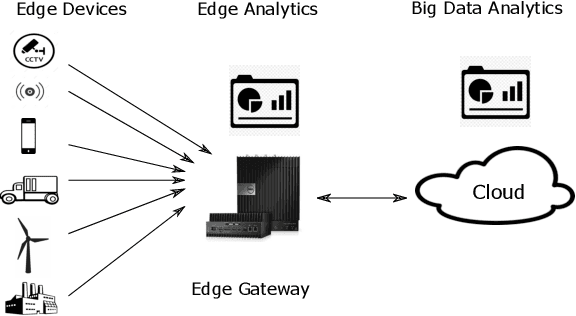
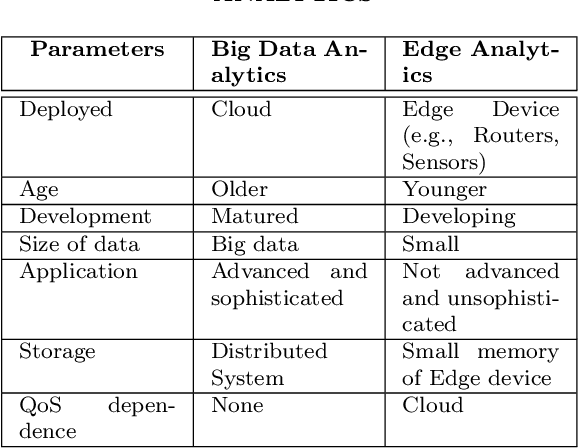
Edge technology aims to bring Cloud resources (specifically, the compute, storage, and network) to the closed proximity of the Edge devices, i.e., smart devices where the data are produced and consumed. Embedding computing and application in Edge devices lead to emerging of two new concepts in Edge technology, namely, Edge computing and Edge analytics. Edge analytics uses some techniques or algorithms to analyze the data generated by the Edge devices. With the emerging of Edge analytics, the Edge devices have become a complete set. Currently, Edge analytics is unable to provide full support for the execution of the analytic techniques. The Edge devices cannot execute advanced and sophisticated analytic algorithms following various constraints such as limited power supply, small memory size, limited resources, etc. This article aims to provide a detailed discussion on Edge analytics. A clear explanation to distinguish between the three concepts of Edge technology, namely, Edge devices, Edge computing, and Edge analytics, along with their issues. Furthermore, the article discusses the implementation of Edge analytics to solve many problems in various areas such as retail, agriculture, industry, and healthcare. In addition, the research papers of the state-of-the-art edge analytics are rigorously reviewed in this article to explore the existing issues, emerging challenges, research opportunities and their directions, and applications.
deepBF: Malicious URL detection using Learned Bloom Filter and Evolutionary Deep Learning
Mar 18, 2021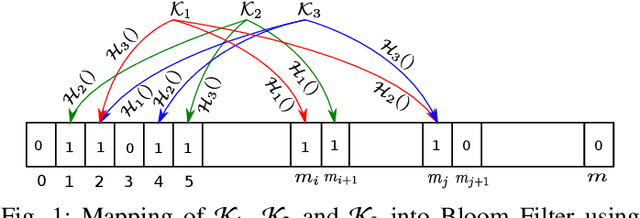
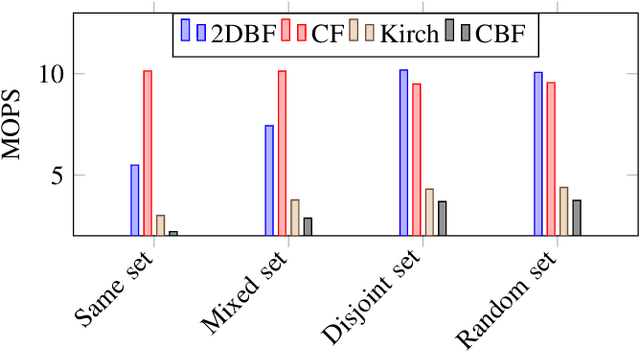
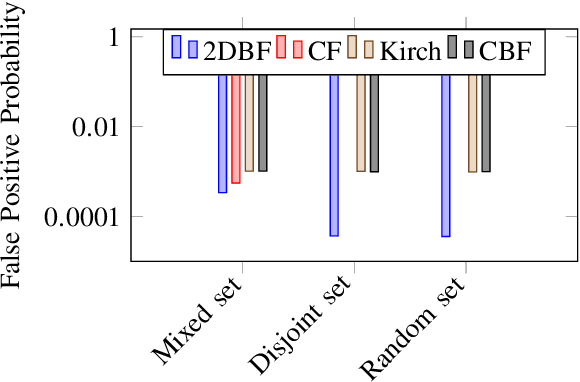
Malicious URL detection is an emerging research area due to continuous modernization of various systems, for instance, Edge Computing. In this article, we present a novel malicious URL detection technique, called deepBF (deep learning and Bloom Filter). deepBF is presented in two-fold. Firstly, we propose a learned Bloom Filter using 2-dimensional Bloom Filter. We experimentally decide the best non-cryptography string hash function. Then, we derive a modified non-cryptography string hash function from the selected hash function for deepBF by introducing biases in the hashing method and compared among the string hash functions. The modified string hash function is compared to other variants of diverse non-cryptography string hash functions. It is also compared with various filters, particularly, counting Bloom Filter, Kirsch \textit{et al.}, and Cuckoo Filter using various use cases. The use cases unearth weakness and strength of the filters. Secondly, we propose a malicious URL detection mechanism using deepBF. We apply the evolutionary convolutional neural network to identify the malicious URLs. The evolutionary convolutional neural network is trained and tested with malicious URL datasets. The output is tested in deepBF for accuracy. We have achieved many conclusions from our experimental evaluation and results and are able to reach various conclusive decisions which are presented in the article.
Empirical Study on Airline Delay Analysis and Prediction
Feb 17, 2020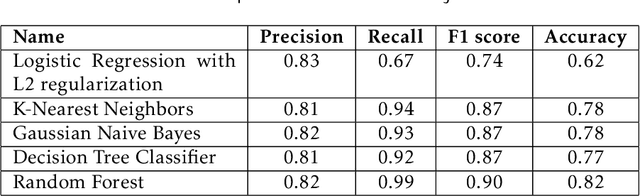
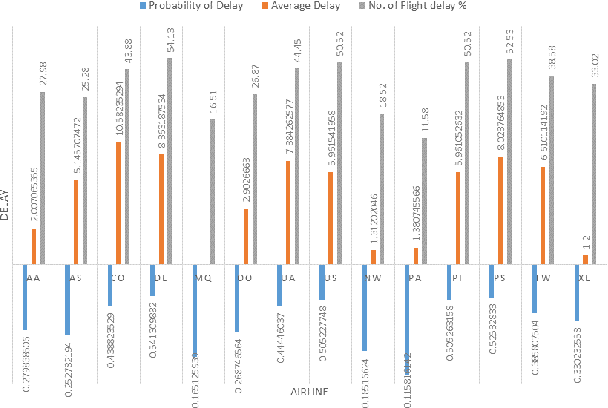
The Big Data analytics are a logical analysis of very large scale datasets. The data analysis enhances an organization and improve the decision making process. In this article, we present Airline Delay Analysis and Prediction to analyze airline datasets with the combination of weather dataset. In this research work, we consider various attributes to analyze flight delay, for example, day-wise, airline-wise, cloud cover, temperature, etc. Moreover, we present rigorous experiments on various machine learning model to predict correctly the delay of a flight, namely, logistic regression with L2 regularization, Gaussian Naive Bayes, K-Nearest Neighbors, Decision Tree classifier and Random forest model. The accuracy of the Random Forest model is 82% with a delay threshold of 15 minutes of flight delay. The analysis is carried out using dataset from 1987 to 2008, the training is conducted with dataset from 2000 to 2007 and validated prediction result using 2008 data. Moreover, we have got recall 99% in the Random Forest model.
Machine Learning: A Dark Side of Cancer Computing
Mar 17, 2019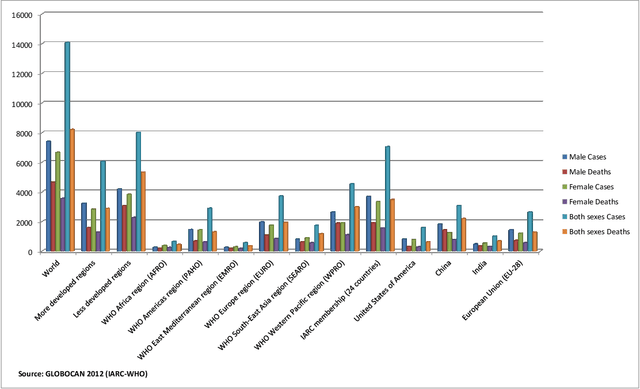

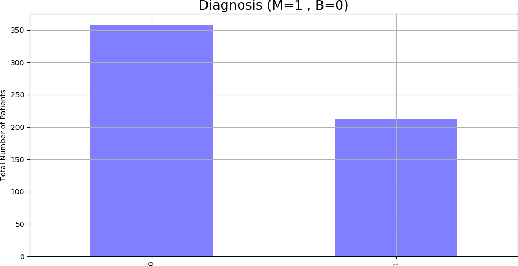
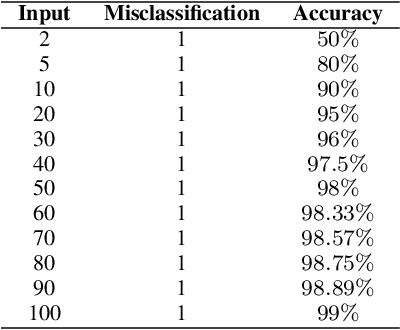
Cancer analysis and prediction is the utmost important research field for well-being of humankind. The Cancer data are analyzed and predicted using machine learning algorithms. Most of the researcher claims the accuracy of the predicted results within 99%. However, we show that machine learning algorithms can easily predict with an accuracy of 100% on Wisconsin Diagnostic Breast Cancer dataset. We show that the method of gaining accuracy is an unethical approach that we can easily mislead the algorithms. In this paper, we exploit the weakness of Machine Learning algorithms. We perform extensive experiments for the correctness of our results to exploit the weakness of machine learning algorithms. The methods are rigorously evaluated to validate our claim. In addition, this paper focuses on correctness of accuracy. This paper report three key outcomes of the experiments, namely, correctness of accuracies, significance of minimum accuracy, and correctness of machine learning algorithms.
* 7 Pages, 21 Figures, 2 Tables, Proceedings of the 2018 International Conference on Bioinformatics and Computational Biology, pp. 92-98, 2018