 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation on Learning, Polluting, and Unlearning the Spam Emails for Lifelong Learning
Paper and Code
Dec 24, 2021
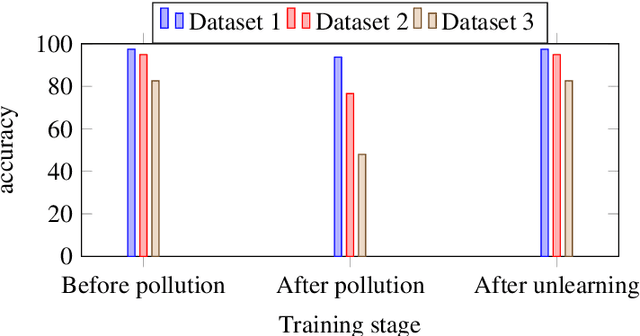
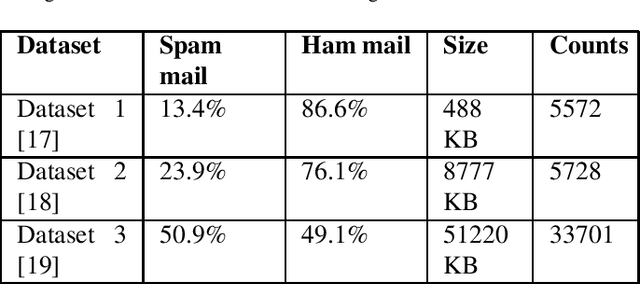
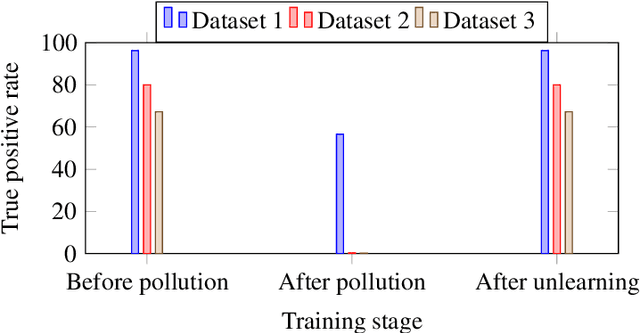
Machine unlearning for security is studied in this context. Several spam email detection methods exist, each of which employs a different algorithm to detect undesired spam emails. But these models are vulnerable to attacks. Many attackers exploit the model by polluting the data, which are trained to the model in various ways. So to act deftly in such situations model needs to readily unlearn the polluted data without the need for retraining. Retraining is impractical in most cases as there is already a massive amount of data trained to the model in the past, which needs to be trained again just for removing a small amount of polluted data, which is often significantly less than 1%. This problem can be solved by developing unlearning frameworks for all spam detection models. In this research, unlearning module is integrated into spam detection models that are based on Naive Bayes, Decision trees, and Random Forests algorithms. To assess the benefits of unlearning over retraining, three spam detection models are polluted and exploited by taking attackers' positions and proving models' vulnerability. Reduction in accuracy and true positive rates are shown in each case showing the effect of pollution on models. Then unlearning modules are integrated into the models, and polluted data is unlearned; on testing the models after unlearning, restoration of performance is seen. Also, unlearning and retraining times are compared with different pollution data sizes on all models. On analyzing the findings, it can be concluded that unlearning is considerably superior to retraining. Results show that unlearning is fast, easy to implement, easy to use, and effective.