 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging wisdom of the crowds to improve consensus among radiologists by real time, blinded collaborations on a digital swarm platform
Jun 26, 2021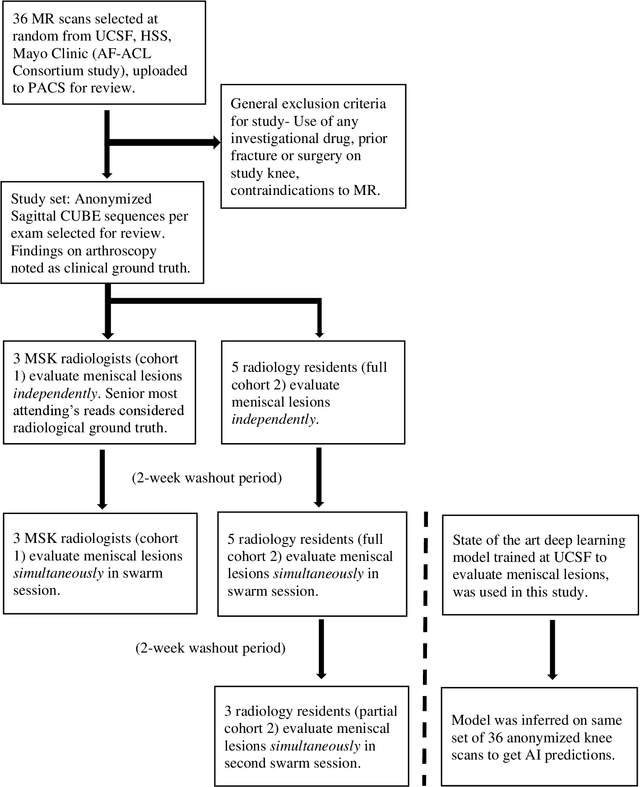
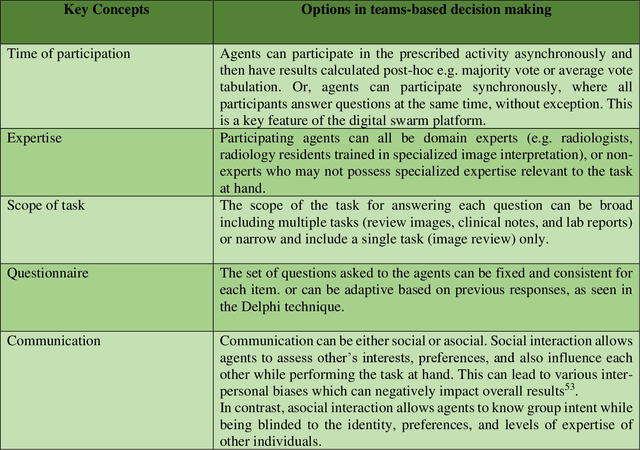
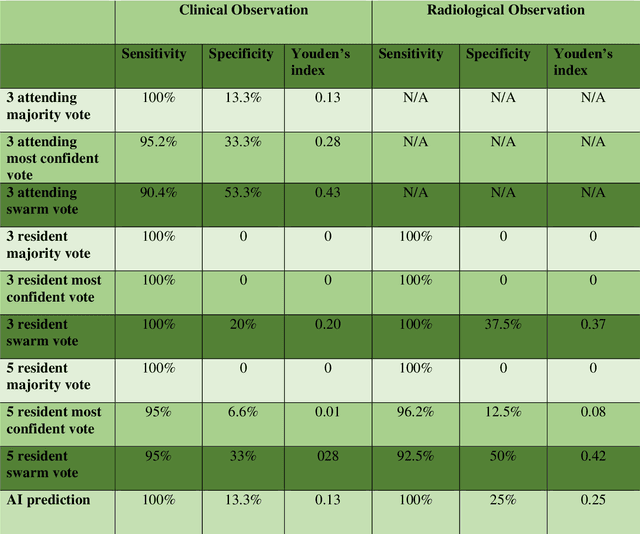
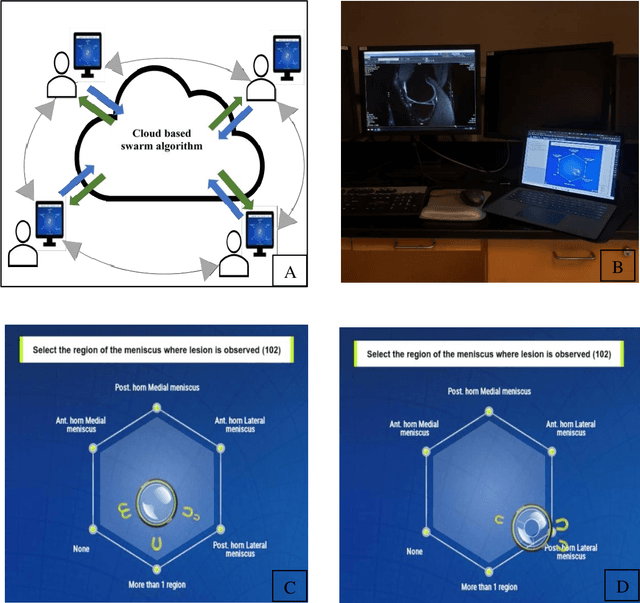
Radiologists today play a key role in making diagnostic decisions and labeling images for training A.I. algorithms. Low inter-reader reliability (IRR) can be seen between experts when interpreting challenging cases. While teams-based decisions are known to outperform individual decisions, inter-personal biases often creep up in group interactions which limit non-dominant participants from expressing true opinions. To overcome the dual problems of low consensus and inter-personal bias, we explored a solution modeled on biological swarms of bees. Two separate cohorts; three radiologists and five radiology residents collaborated on a digital swarm platform in real time and in a blinded fashion, grading meniscal lesions on knee MR exams. These consensus votes were benchmarked against clinical (arthroscopy) and radiological (senior-most radiologist) observations. The IRR of the consensus votes was compared to the IRR of the majority and most confident votes of the two cohorts.The radiologist cohort saw an improvement of 23% in IRR of swarm votes over majority vote. Similar improvement of 23% in IRR in 3-resident swarm votes over majority vote, was observed. The 5-resident swarm had an even higher improvement of 32% in IRR over majority vote. Swarm consensus votes also improved specificity by up to 50%. The swarm consensus votes outperformed individual and majority vote decisions in both the radiologists and resident cohorts. The 5-resident swarm had higher IRR than 3-resident swarm indicating positive effect of increased swarm size. The attending and resident swarms also outperformed predictions from a state-of-the-art A.I. algorithm. Utilizing a digital swarm platform improved agreement and allows participants to express judgement free intent, resulting in superior clinical performance and robust A.I. training labels.
Automatic Hip Fracture Identification and Functional Subclassification with Deep Learning
Sep 10, 2019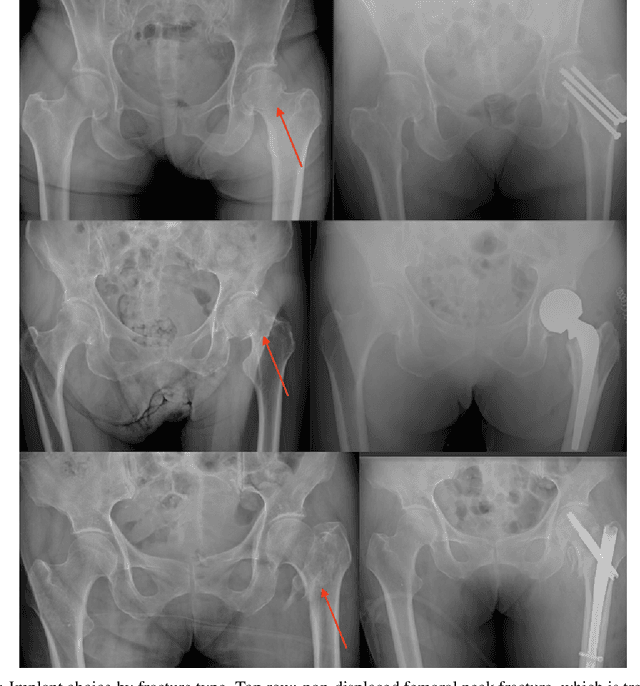
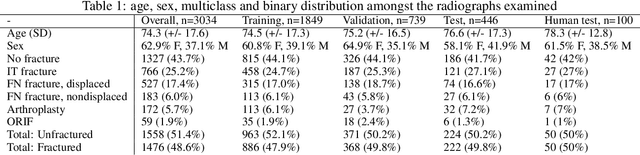
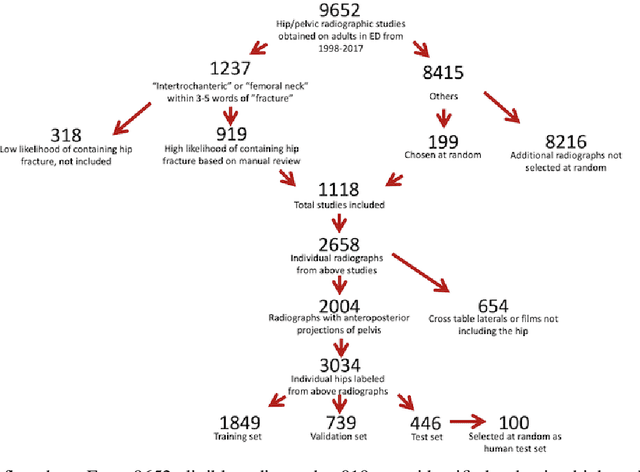
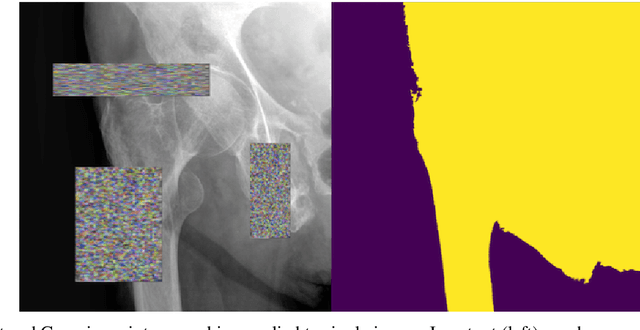
Purpose: Hip fractures are a common cause of morbidity and mortality. Automatic identification and classification of hip fractures using deep learning may improve outcomes by reducing diagnostic errors and decreasing time to operation. Methods: Hip and pelvic radiographs from 1118 studies were reviewed and 3034 hips were labeled via bounding boxes and classified as normal, displaced femoral neck fracture, nondisplaced femoral neck fracture, intertrochanteric fracture, previous ORIF, or previous arthroplasty. A deep learning-based object detection model was trained to automate the placement of the bounding boxes. A Densely Connected Convolutional Neural Network (DenseNet) was trained on a subset of the bounding box images, and its performance evaluated on a held out test set and by comparison on a 100-image subset to two groups of human observers: fellowship-trained radiologists and orthopaedists, and senior residents in emergency medicine, radiology, and orthopaedics. Results: The binary accuracy for fracture of our model was 93.8% (95% CI, 91.3-95.8%), with sensitivity of 92.7% (95% CI, 88.7-95.6%), and specificity 95.0% (95% CI, 91.5-97.3%). Multiclass classification accuracy was 90.4% (95% CI, 87.4-92.9%). When compared to human observers, our model achieved at least expert-level classification under all conditions. Additionally, when the model was used as an aid, human performance improved, with aided resident performance approximating unaided fellowship-trained expert performance. Conclusions: Our deep learning model identified and classified hip fractures with at least expert-level accuracy, and when used as an aid improved human performance, with aided resident performance approximating that of unaided fellowship-trained attendings.