 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging wisdom of the crowds to improve consensus among radiologists by real time, blinded collaborations on a digital swarm platform
Jun 26, 2021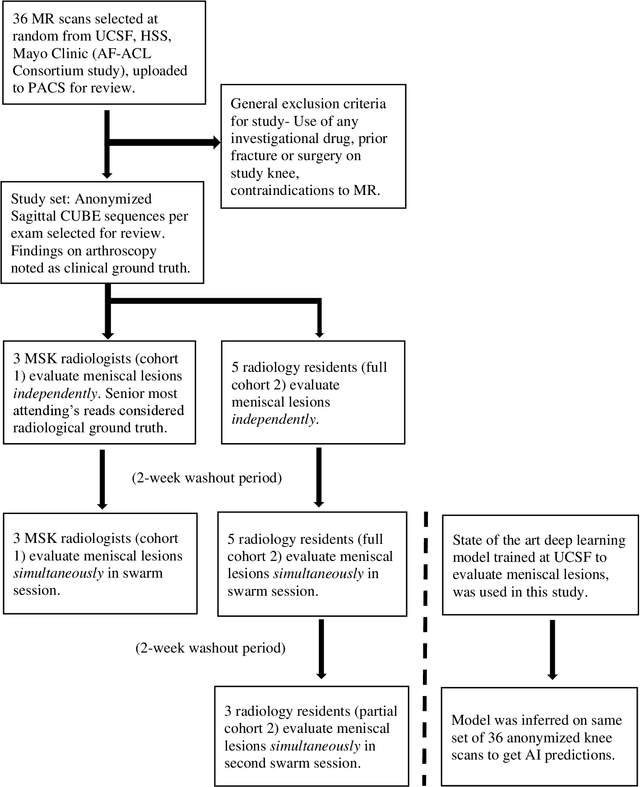
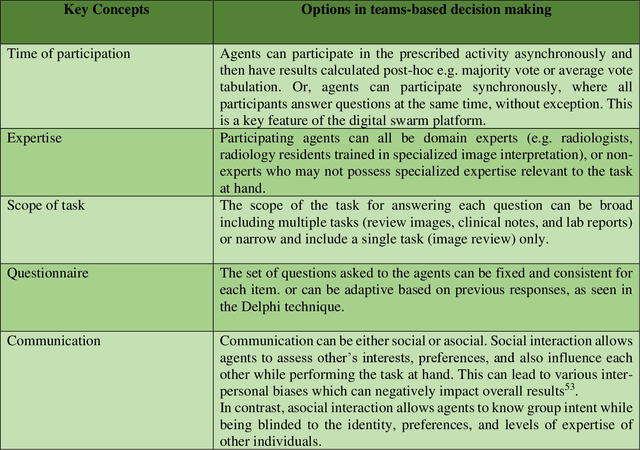
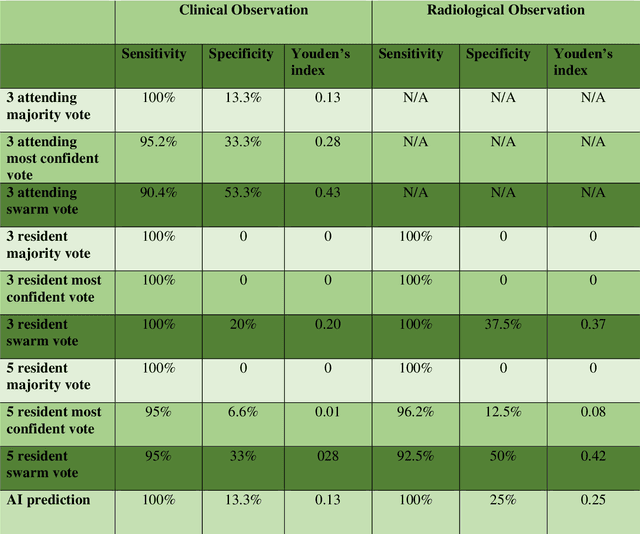
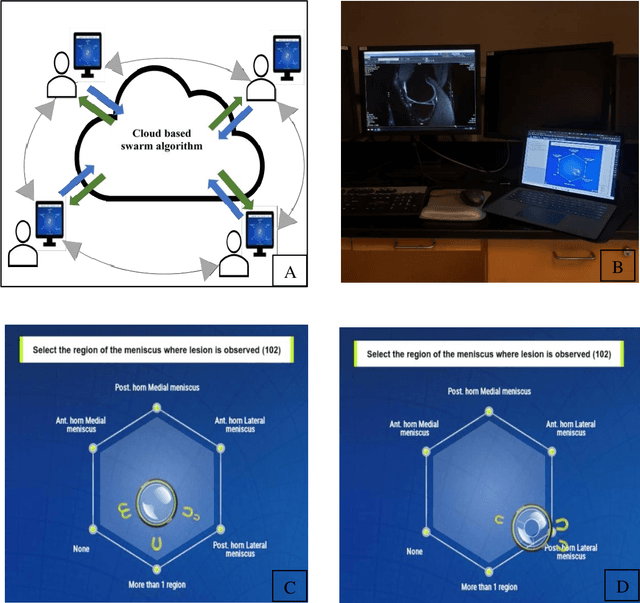
Radiologists today play a key role in making diagnostic decisions and labeling images for training A.I. algorithms. Low inter-reader reliability (IRR) can be seen between experts when interpreting challenging cases. While teams-based decisions are known to outperform individual decisions, inter-personal biases often creep up in group interactions which limit non-dominant participants from expressing true opinions. To overcome the dual problems of low consensus and inter-personal bias, we explored a solution modeled on biological swarms of bees. Two separate cohorts; three radiologists and five radiology residents collaborated on a digital swarm platform in real time and in a blinded fashion, grading meniscal lesions on knee MR exams. These consensus votes were benchmarked against clinical (arthroscopy) and radiological (senior-most radiologist) observations. The IRR of the consensus votes was compared to the IRR of the majority and most confident votes of the two cohorts.The radiologist cohort saw an improvement of 23% in IRR of swarm votes over majority vote. Similar improvement of 23% in IRR in 3-resident swarm votes over majority vote, was observed. The 5-resident swarm had an even higher improvement of 32% in IRR over majority vote. Swarm consensus votes also improved specificity by up to 50%. The swarm consensus votes outperformed individual and majority vote decisions in both the radiologists and resident cohorts. The 5-resident swarm had higher IRR than 3-resident swarm indicating positive effect of increased swarm size. The attending and resident swarms also outperformed predictions from a state-of-the-art A.I. algorithm. Utilizing a digital swarm platform improved agreement and allows participants to express judgement free intent, resulting in superior clinical performance and robust A.I. training labels.
On Ensemble Learning
Mar 07, 2021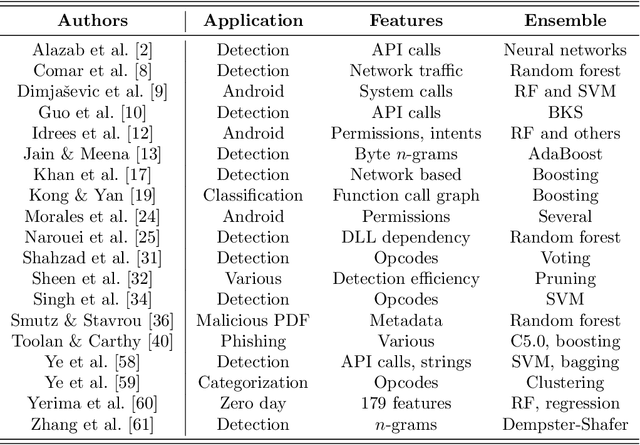
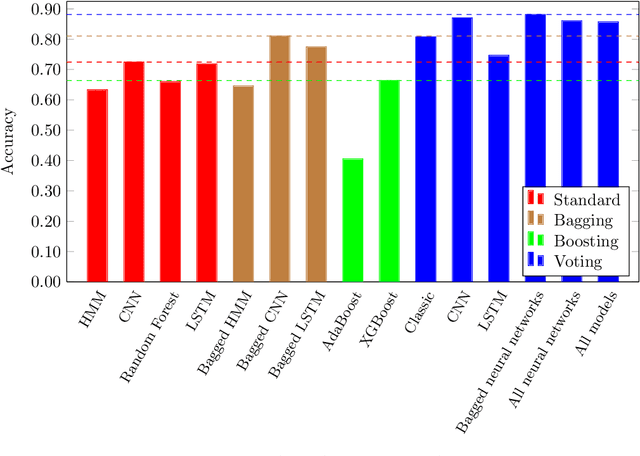
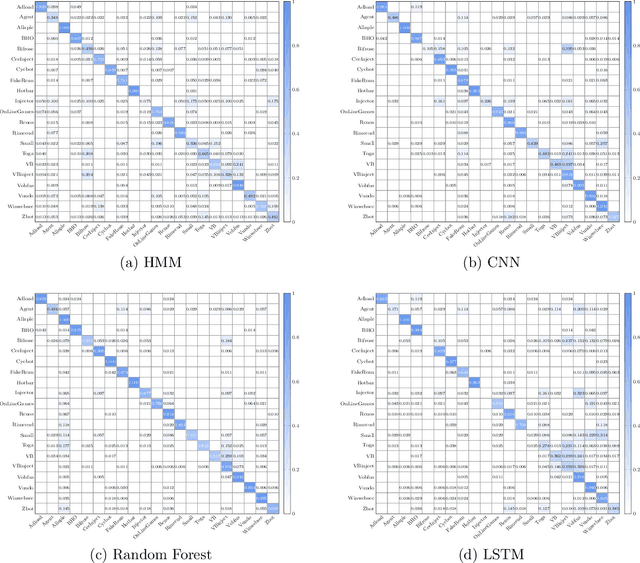
In this paper, we consider ensemble classifiers, that is, machine learning based classifiers that utilize a combination of scoring functions. We provide a framework for categorizing such classifiers, and we outline several ensemble techniques, discussing how each fits into our framework. From this general introduction, we then pivot to the topic of ensemble learning within the context of malware analysis. We present a brief survey of some of the ensemble techniques that have been used in malware (and related) research. We conclude with an extensive set of experiments, where we apply ensemble techniques to a large and challenging malware dataset. While many of these ensemble techniques have appeared in the malware literature, previously there has been no way to directly compare results such as these, as different datasets and different measures of success are typically used. Our common framework and empirical results are an effort to bring some sense of order to the chaos that is evident in the evolving field of ensemble learning -- both within the narrow confines of the malware analysis problem, and in the larger realm of machine learning in general.