 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical NER for the Enterprise with Distillated BERN2 and the Kazu Framework
Dec 01, 2022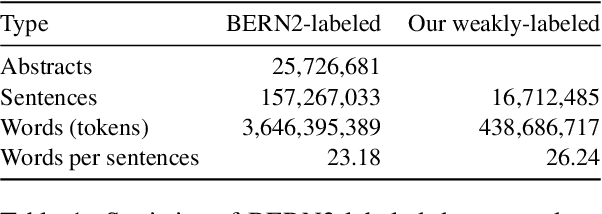
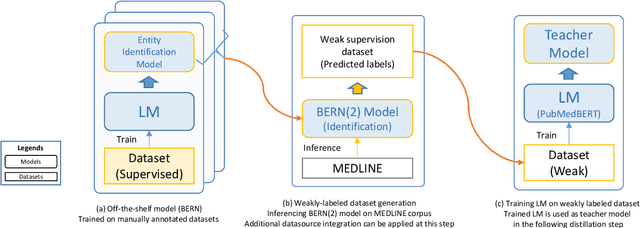
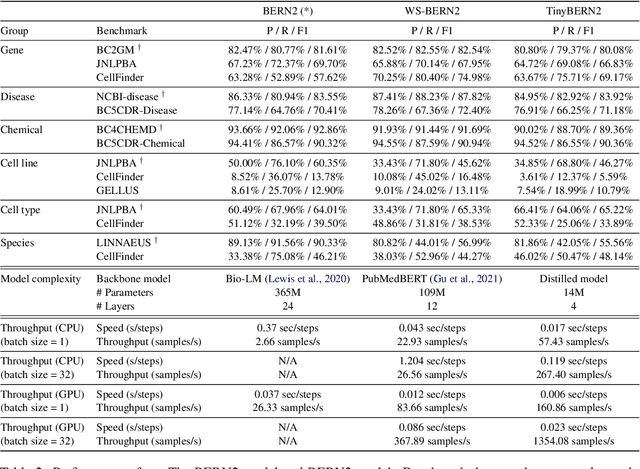
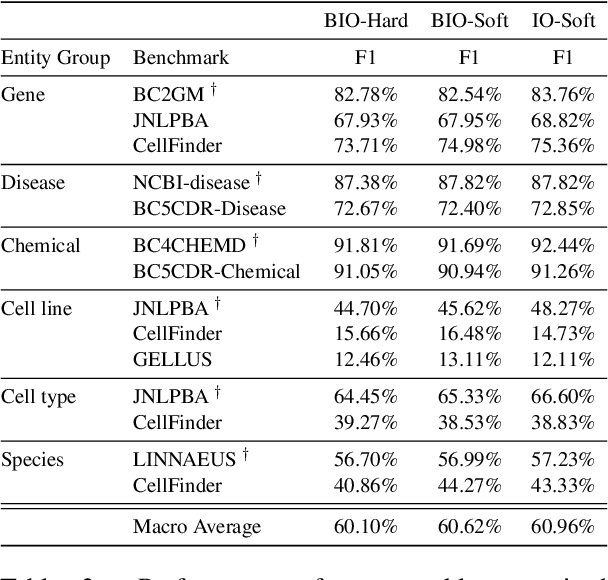
In order to assist the drug discovery/development process, pharmaceutical companies often apply biomedical NER and linking techniques over internal and public corpora. Decades of study of the field of BioNLP has produced a plethora of algorithms, systems and datasets. However, our experience has been that no single open source system meets all the requirements of a modern pharmaceutical company. In this work, we describe these requirements according to our experience of the industry, and present Kazu, a highly extensible, scalable open source framework designed to support BioNLP for the pharmaceutical sector. Kazu is a built around a computationally efficient version of the BERN2 NER model (TinyBERN2), and subsequently wraps several other BioNLP technologies into one coherent system. KAZU framework is open-sourced: https://github.com/AstraZeneca/KAZU
Sequence Tagging for Biomedical Extractive Question Answering
Apr 15, 2021
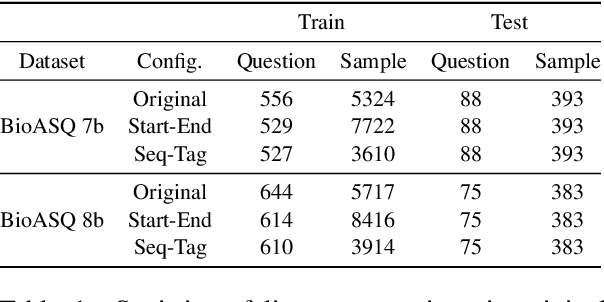
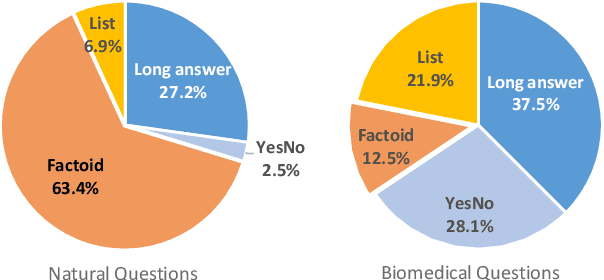
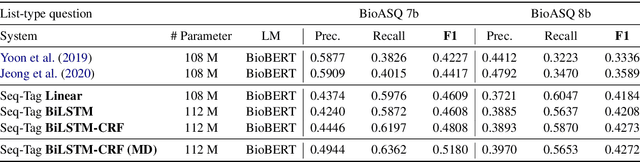
Current studies in extractive question answering (EQA) have modeled single-span extraction setting, where a single answer span is a label to predict for a given question-passage pair. This setting is natural for general domain EQA as the majority of the questions in the general domain can be answered with a single span. Following general domain EQA models, current biomedical EQA (BioEQA) models utilize single-span extraction setting with post-processing steps. In this paper, we investigate the difference of the question distribution across the general and biomedical domains and discover biomedical questions are more likely to require list-type answers (multiple answers) than factoid-type answers (single answer). In real-world use cases, this emphasizes the need for Biomedical EQA models able to handle multiple question types. Based on this preliminary study, we propose a multi-span extraction setting, namely sequence tagging approach for BioEQA, which directly tackles questions with a variable number of phrases as their answer. Our approach can learn to decide the number of answers for a question from training data. Our experimental result on the BioASQ 7b and 8b list-type questions outperformed the best-performing existing models without requiring post-processing steps.