 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Anytime Algorithm for Task and Motion MDPs
Feb 16, 2018
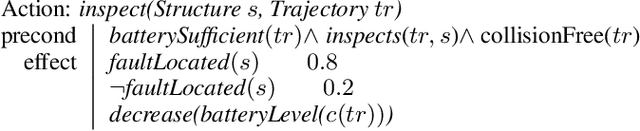
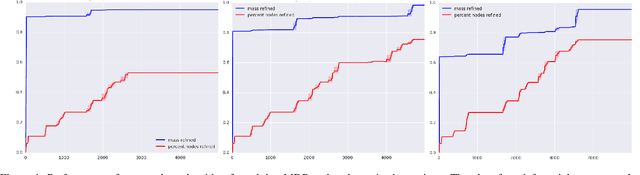
Integrated task and motion planning has emerged as a challenging problem in sequential decision making, where a robot needs to compute high-level strategy and low-level motion plans for solving complex tasks. While high-level strategies require decision making over longer time-horizons and scales, their feasibility depends on low-level constraints based upon the geometries and continuous dynamics of the environment. The hybrid nature of this problem makes it difficult to scale; most existing approaches focus on deterministic, fully observable scenarios. We present a new approach where the high-level decision problem occurs in a stochastic setting and can be modeled as a Markov decision process. In contrast to prior efforts, we show that complete MDP policies, or contingent behaviors, can be computed effectively in an anytime fashion. Our algorithm continuously improves the quality of the solution and is guaranteed to be probabilistically complete. We evaluate the performance of our approach on a challenging, realistic test problem: autonomous aircraft inspection. Our results show that we can effectively compute consistent task and motion policies for the most likely execution-time outcomes using only a fraction of the computation required to develop the complete task and motion policy.