 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of High-Dimensional Regression Coefficients by Comparison with Linearized Compressing Features
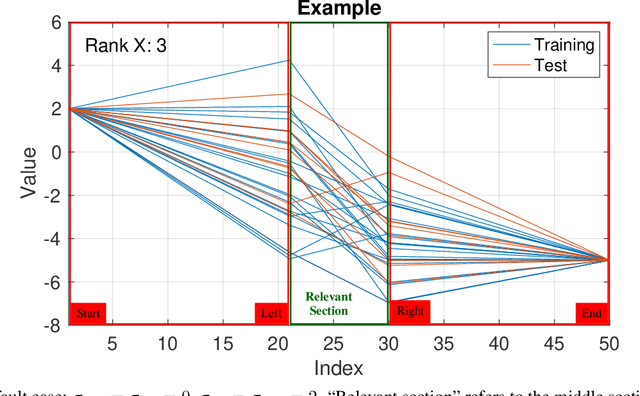
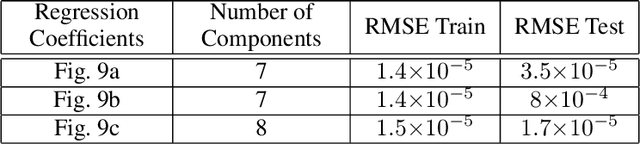
Nov 18, 2024Linear regression is often deemed inherently interpretable; however, challenges arise for high-dimensional data. We focus on further understanding how linear regression approximates nonlinear responses from high-dimensional functional data, motivated by predicting cycle life for lithium-ion batteries. We develop a linearization method to derive feature coefficients, which we compare with the closest regression coefficients of the path of regression solutions. We showcase the methods on battery data case studies where a single nonlinear compressing feature, $g\colon \mathbb{R}^p \to \mathbb{R}$, is used to construct a synthetic response, $\mathbf{y} \in \mathbb{R}$. This unifying view of linear regression and compressing features for high-dimensional functional data helps to understand (1) how regression coefficients are shaped in the highly regularized domain and how they relate to linearized feature coefficients and (2) how the shape of regression coefficients changes as a function of regularization to approximate nonlinear responses by exploiting local structures.
Latent Variable Method Demonstrator -- Software for Understanding Multivariate Data Analytics Algorithms
May 17, 2022

The ever-increasing quantity of multivariate process data is driving a need for skilled engineers to analyze, interpret, and build models from such data. Multivariate data analytics relies heavily on linear algebra, optimization, and statistics and can be challenging for students to understand given that most curricula do not have strong coverage in the latter three topics. This article describes interactive software -- the Latent Variable Demonstrator (LAVADE) -- for teaching, learning, and understanding latent variable methods. In this software, users can interactively compare latent variable methods such as Partial Least Squares (PLS), and Principal Component Regression (PCR) with other regression methods such as Least Absolute Shrinkage and Selection Operator (lasso), Ridge Regression (RR), and Elastic Net (EN). LAVADE helps to build intuition on choosing appropriate methods, hyperparameter tuning, and model coefficient interpretation, fostering a conceptual understanding of the algorithms' differences. The software contains a data generation method and three chemical process datasets, allowing for comparing results of datasets with different levels of complexity. LAVADE is released as open-source software so that others can apply and advance the tool for use in teaching or research.