 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsRec: A Novel Meta-Learning Approach to Recommending Bibliographic Reference Parsers
Nov 26, 2018

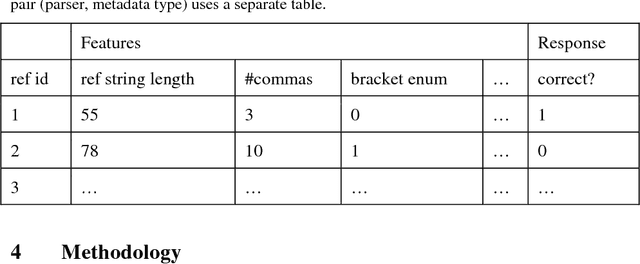
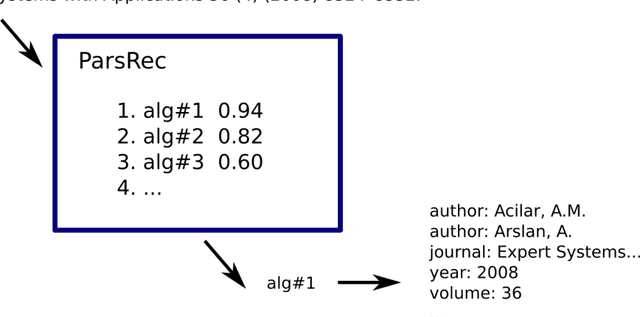
Bibliographic reference parsers extract machine-readable metadata such as author names, title, journal, and year from bibliographic reference strings. To extract the metadata, the parsers apply heuristics or machine learning. However, no reference parser, and no algorithm, consistently gives the best results in every scenario. For instance, one tool may be best in extracting titles in ACM citation style, but only third best when APA is used. Another tool may be best in extracting English author names, while another one is best for noisy data (i.e. inconsistent citation styles). In this paper, which is an extended version of our recent RecSys poster, we address the problem of reference parsing from a recommender-systems and meta-learning perspective. We propose ParsRec, a meta-learning based recommender-system that recommends the potentially most effective parser for a given reference string. ParsRec recommends one out of 10 open-source parsers: Anystyle-Parser, Biblio, CERMINE, Citation, Citation-Parser, GROBID, ParsCit, PDFSSA4MET, Reference Tagger, and Science Parse. We evaluate ParsRec on 105k references from chemistry. We propose two approaches to meta-learning recommendations. The first approach learns the best parser for an entire reference string. The second approach learns the best parser for each metadata type in a reference string. The second approach achieved a 2.6% increase in F1 (0.909 vs. 0.886) over the best single parser (GROBID), reducing the false positive rate by 20.2% (0.075 vs. 0.094), and the false negative rate by 18.9% (0.107 vs. 0.132).