 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained language model transfer on neural named entity recognition in Indonesian conversational texts
Feb 21, 2019
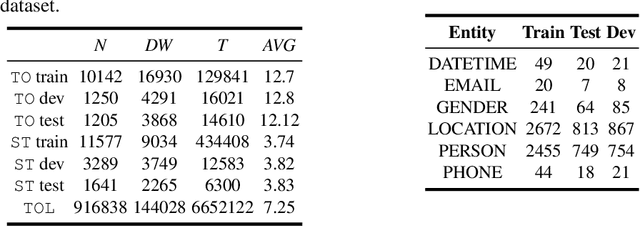

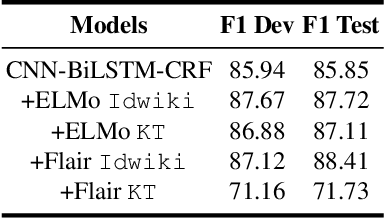
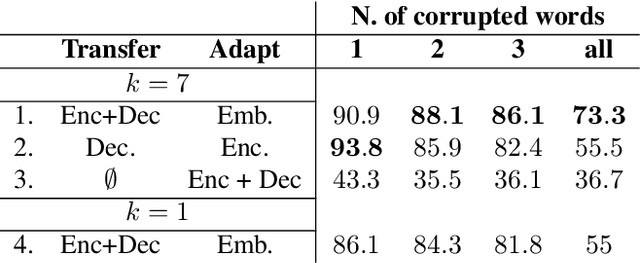
Named entity recognition (NER) is an important task in NLP, which is all the more challenging in conversational domain with their noisy facets. Moreover, conversational texts are often available in limited amount, making supervised tasks infeasible. To learn from small data, strong inductive biases are required. Previous work relied on hand-crafted features to encode these biases until transfer learning emerges. Here, we explore a transfer learning method, namely language model pretraining, on NER task in Indonesian conversational texts. We utilize large unlabeled data (generic domain) to be transferred to conversational texts, enabling supervised training on limited in-domain data. We report two transfer learning variants, namely supervised model fine-tuning and unsupervised pretrained LM fine-tuning. Our experiments show that both variants outperform baseline neural models when trained on small data (100 sentences), yielding an absolute improvement of 32 points of test F1 score. Furthermore, we find that the pretrained LM encodes part-of-speech information which is a strong predictor for NER.
The Fast and the Flexible: training neural networks to learn to follow instructions from small data
Sep 17, 2018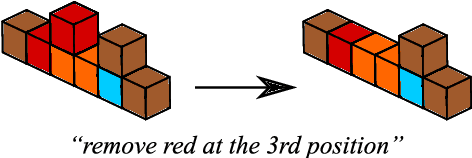

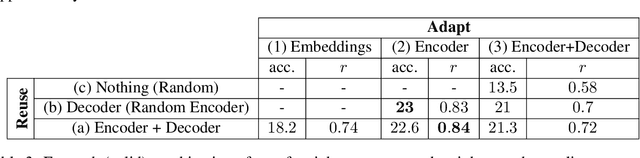
Learning to follow human instructions is a challenging task because while interpreting instructions requires discovering arbitrary algorithms, humans typically provide very few examples to learn from. For learning from this data to be possible, strong inductive biases are necessary. Work in the past has relied on hand-coded components or manually engineered features to provide such biases. In contrast, here we seek to establish whether this knowledge can be acquired automatically by a neural network system through a two phase training procedure: A (slow) offline learning stage where the network learns about the general structure of the task and a (fast) online adaptation phase where the network learns the language of a new given speaker. Controlled experiments show that when the network is exposed to familiar instructions but containing novel words, the model adapts very efficiently to the new vocabulary. Moreover, even for human speakers whose language usage can depart significantly from our artificial training language, our network can still make use of its automatically acquired inductive bias to learn to follow instructions more effectively.