 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term foehn reconstruction combining unsupervised and supervised learning
Jun 03, 2024Foehn winds, characterized by abrupt temperature increases and wind speed changes, significantly impact regions on the leeward side of mountain ranges, e.g., by spreading wildfires. Understanding how foehn occurrences change under climate change is crucial. Unfortunately, foehn cannot be measured directly but has to be inferred from meteorological measurements employing suitable classification schemes. Hence, this approach is typically limited to specific periods for which the necessary data are available. We present a novel approach for reconstructing historical foehn occurrences using a combination of unsupervised and supervised probabilistic statistical learning methods. We utilize in-situ measurements (available for recent decades) to train an unsupervised learner (finite mixture model) for automatic foehn classification. These labeled data are then linked to reanalysis data (covering longer periods) using a supervised learner (lasso or boosting). This allows to reconstruct past foehn probabilities based solely on reanalysis data. Applying this method to ERA5 reanalysis data for six stations across Switzerland and Austria achieves accurate hourly reconstructions of north and south foehn occurrence, respectively, dating back to 1940. This paves the way for investigating how seasonal foehn patterns have evolved over the past 83 years, providing valuable insights into climate change impacts on these critical wind events.
Stagewise Boosting Distributional Regression
May 28, 2024
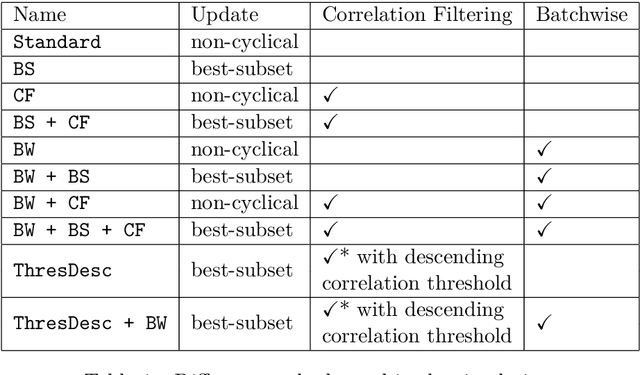


Forward stagewise regression is a simple algorithm that can be used to estimate regularized models. The updating rule adds a small constant to a regression coefficient in each iteration, such that the underlying optimization problem is solved slowly with small improvements. This is similar to gradient boosting, with the essential difference that the step size is determined by the product of the gradient and a step length parameter in the latter algorithm. One often overlooked challenge in gradient boosting for distributional regression is the issue of a vanishing small gradient, which practically halts the algorithm's progress. We show that gradient boosting in this case oftentimes results in suboptimal models, especially for complex problems certain distributional parameters are never updated due to the vanishing gradient. Therefore, we propose a stagewise boosting-type algorithm for distributional regression, combining stagewise regression ideas with gradient boosting. Additionally, we extend it with a novel regularization method, correlation filtering, to provide additional stability when the problem involves a large number of covariates. Furthermore, the algorithm includes best-subset selection for parameters and can be applied to big data problems by leveraging stochastic approximations of the updating steps. Besides the advantage of processing large datasets, the stochastic nature of the approximations can lead to better results, especially for complex distributions, by reducing the risk of being trapped in a local optimum. The performance of our proposed stagewise boosting distributional regression approach is investigated in an extensive simulation study and by estimating a full probabilistic model for lightning counts with data of more than 9.1 million observations and 672 covariates.