 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetherlands Dataset: A New Public Dataset for Machine Learning in Seismic Interpretation
Mar 26, 2019
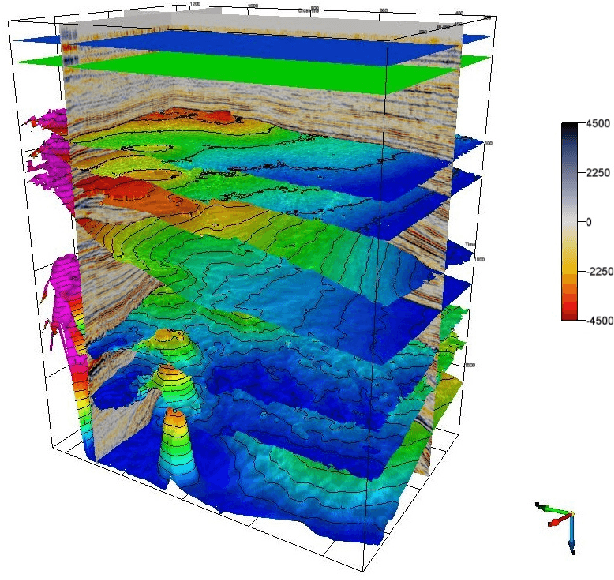
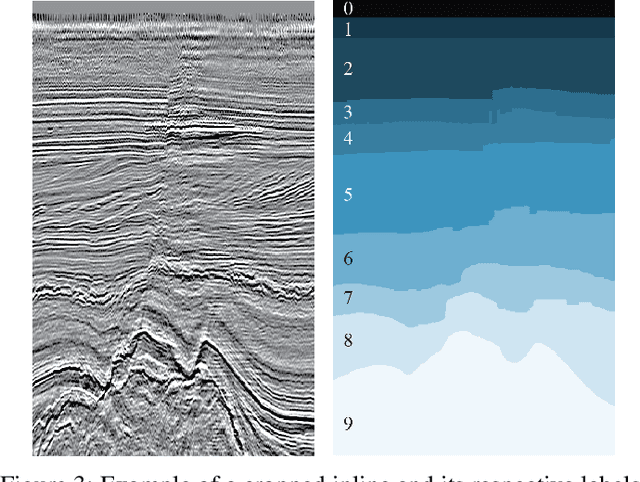
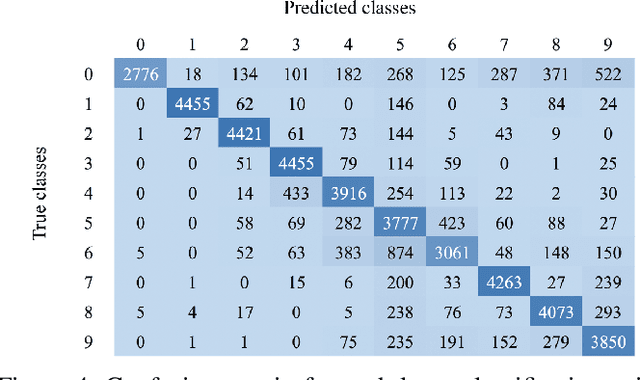
Machine learning and, more specifically, deep learning algorithms have seen remarkable growth in their popularity and usefulness in the last years. This is arguably due to three main factors: powerful computers, new techniques to train deeper networks and larger datasets. Although the first two are readily available in modern computers and ML libraries, the last one remains a challenge for many domains. It is a fact that big data is a reality in almost all fields nowadays, and geosciences are not an exception. However, to achieve the success of general-purpose applications such as ImageNet - for which there are +14 million labeled images for 1000 target classes - we not only need more data, we need more high-quality labeled data. When it comes to the Oil&Gas industry, confidentiality issues hamper even more the sharing of datasets. In this work, we present the Netherlands interpretation dataset, a contribution to the development of machine learning in seismic interpretation. The Netherlands F3 dataset acquisition was carried out in the North Sea, Netherlands offshore. The data is publicly available and contains pos-stack data, 8 horizons and well logs of 4 wells. For the purposes of our machine learning tasks, the original dataset was reinterpreted, generating 9 horizons separating different seismic facies intervals. The interpreted horizons were used to generate approximatelly 190,000 labeled images for inlines and crosslines. Finally, we present two deep learning applications in which the proposed dataset was employed and produced compelling results.