 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Learning for Handwritten Page Segmentation
Jan 19, 2021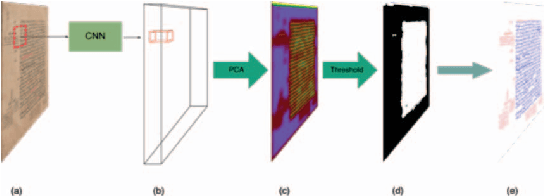



Segmenting handwritten document images into regions with homogeneous patterns is an important pre-processing step for many document images analysis tasks. Hand-labeling data to train a deep learning model for layout analysis requires significant human effort. In this paper, we present an unsupervised deep learning method for page segmentation, which revokes the need for annotated images. A siamese neural network is trained to differentiate between patches using their measurable properties such as number of foreground pixels, and average component height and width. The network is trained that spatially nearby patches are similar. The network's learned features are used for page segmentation, where patches are classified as main and side text based on the extracted features. We tested the method on a dataset of handwritten document images with quite complex layouts. Our experiments show that the proposed unsupervised method is as effective as typical supervised methods.
Text line extraction using fully convolutional network and energy minimization
Jan 18, 2021



Text lines are important parts of handwritten document images and easier to analyze by further applications. Despite recent progress in text line detection, text line extraction from a handwritten document remains an unsolved task. This paper proposes to use a fully convolutional network for text line detection and energy minimization for text line extraction. Detected text lines are represented by blob lines that strike through the text lines. These blob lines assist an energy function for text line extraction. The detection stage can locate arbitrarily oriented text lines. Furthermore, the extraction stage is capable of finding out the pixels of text lines with various heights and interline proximity independent of their orientations. Besides, it can finely split the touching and overlapping text lines without an orientation assumption. We evaluate the proposed method on VML-AHTE, VML-MOC, and Diva-HisDB datasets. The VML-AHTE dataset contains overlapping, touching and close text lines with rich diacritics. The VML-MOC dataset is very challenging by its multiply oriented and skewed text lines. The Diva-HisDB dataset exhibits distinct text line heights and touching text lines. The results demonstrate the effectiveness of the method despite various types of challenges, yet using the same parameters in all the experiments.