 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText line extraction using fully convolutional network and energy minimization
Jan 18, 2021



Text lines are important parts of handwritten document images and easier to analyze by further applications. Despite recent progress in text line detection, text line extraction from a handwritten document remains an unsolved task. This paper proposes to use a fully convolutional network for text line detection and energy minimization for text line extraction. Detected text lines are represented by blob lines that strike through the text lines. These blob lines assist an energy function for text line extraction. The detection stage can locate arbitrarily oriented text lines. Furthermore, the extraction stage is capable of finding out the pixels of text lines with various heights and interline proximity independent of their orientations. Besides, it can finely split the touching and overlapping text lines without an orientation assumption. We evaluate the proposed method on VML-AHTE, VML-MOC, and Diva-HisDB datasets. The VML-AHTE dataset contains overlapping, touching and close text lines with rich diacritics. The VML-MOC dataset is very challenging by its multiply oriented and skewed text lines. The Diva-HisDB dataset exhibits distinct text line heights and touching text lines. The results demonstrate the effectiveness of the method despite various types of challenges, yet using the same parameters in all the experiments.
Unsupervised text line segmentation
Mar 19, 2020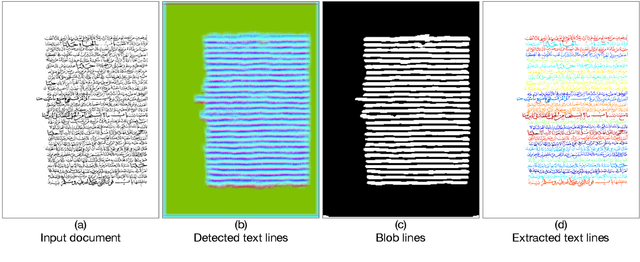



We present an unsupervised text line segmentation method that is inspired by the relative variance between text lines and spaces among text lines. Handwritten text line segmentation is important for the efficiency of further processing. A common method is to train a deep learning network for embedding the document image into an image of blob lines that are tracing the text lines. Previous methods learned such embedding in a supervised manner, requiring the annotation of many document images. This paper presents an unsupervised embedding of document image patches without a need for annotations. The main idea is that the number of foreground pixels over the text lines is relatively different from the number of foreground pixels over the spaces among text lines. Generating similar and different pairs relying on this principle definitely leads to outliers. However, as the results show, the outliers do not harm the convergence and the network learns to discriminate the text lines from the spaces between text lines. We experimented with a challenging Arabic handwritten text line segmentation dataset, VML-AHTE, and achieved a superior performance even over the supervised methods.