 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Not Take It for Granted: Comparing Open-Source Libraries for Software Development Effort Estimation
Jul 04, 2022
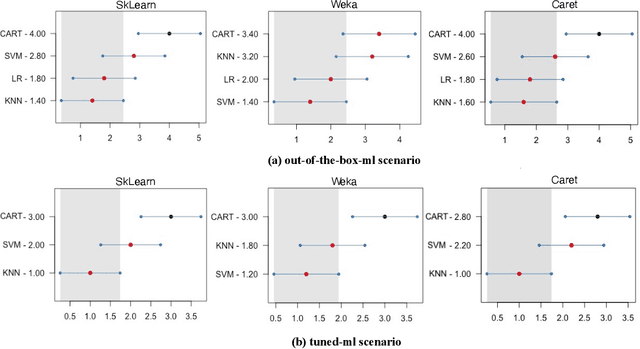
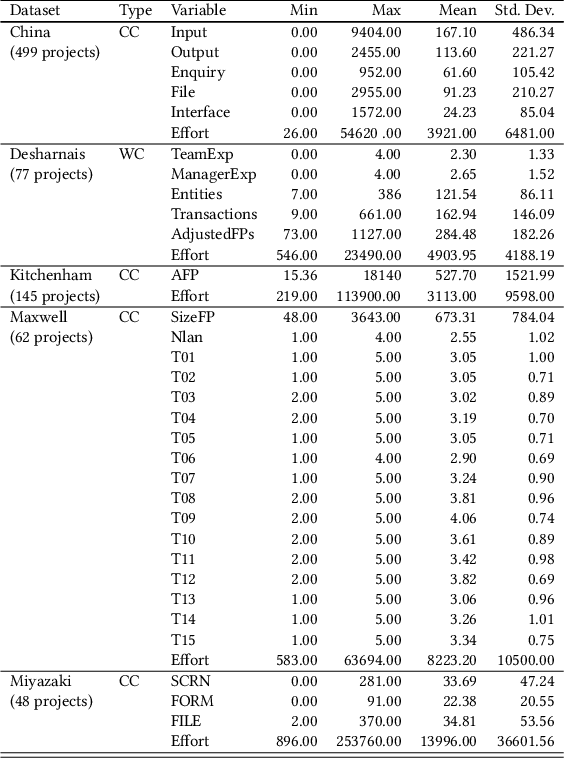
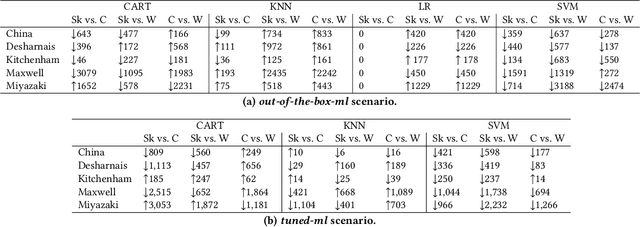
In the past two decades, several Machine Learning (ML) libraries have become freely available. Many studies have used such libraries to carry out empirical investigations on predictive Software Engineering (SE) tasks. However, the differences stemming from using one library over another have been overlooked, implicitly assuming that using any of these libraries would provide the user with the same or very similar results. This paper aims at raising awareness of the differences incurred when using different ML libraries for software development effort estimation (SEE), one of most widely studied SE prediction tasks. To this end, we investigate 4 deterministic machine learners as provided by 3 of the most popular ML open-source libraries written in different languages (namely, Scikit-Learn, Caret and Weka). We carry out a thorough empirical study comparing the performance of the machine learners on 5 SEE datasets in the two most common SEE scenarios (i.e., out-of-the-box-ml and tuned-ml) as well as an in-depth analysis of the documentation and code of their APIs. The results of our study reveal that the predictions provided by the 3 libraries differ in 95% of the cases on average across a total of 105 cases studied. These differences are significantly large in most cases and yield misestimations of up to approx. 3,000 hours per project. Moreover, our API analysis reveals that these libraries provide the user with different levels of control on the parameters one can manipulate, and a lack of clarity and consistency, overall, which might mislead users. Our findings highlight that the ML library is an important design choice for SEE studies, which can lead to a difference in performance. However, such a difference is under-documented. We conclude by highlighting open-challenges with suggestions for the developers of libraries as well as for the researchers and practitioners using them.
Investigating the Use of One-Class Support Vector Machine for Software Defect Prediction
Feb 24, 2022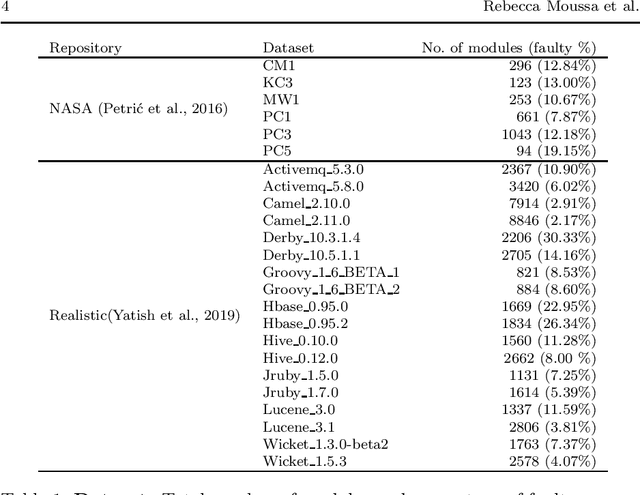

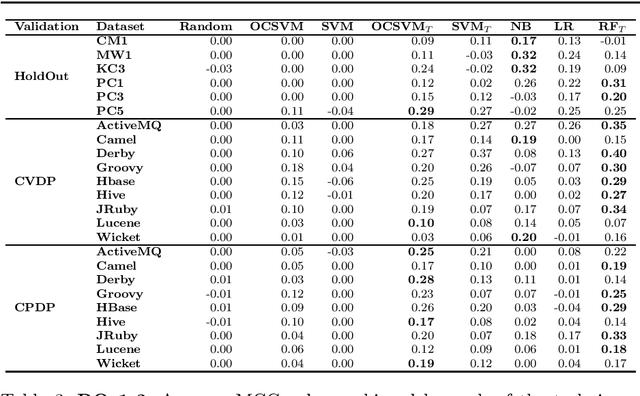
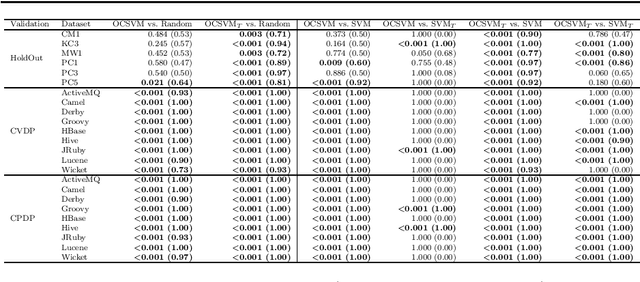
Early software defect identification is considered an important step towards software quality assurance. Software defect prediction aims at identifying software components that are likely to cause faults before a software is made available to the end-user. To date, this task has been modeled as a two-class classification problem, however its nature also allows it to be formulated as a one-class classification task. Preliminary results obtained in prior work show that One-Class Support Vector Machine (OCSVM) can outperform two-class classifiers for defect prediction. If confirmed, these results would overcome the data imbalance problem researchers have for long attempted to tackle in this field. In this paper, we further investigate whether learning from one class only is sufficient to produce effective defect prediction models by conducting a thorough large-scale empirical study investigating 15 real-world software projects, three validation scenarios, eight classifiers, robust evaluation measures and statistical significance tests. The results reveal that OCSVM is more suitable for cross-version and cross-project, rather than for within-project defect prediction, thus suggesting it performs better with heterogeneous data. While, we cannot conclude that OCSVM is the best classifier (Random Forest performs best herein), our results show interesting findings that open up further research avenues for training accurate defect prediction classifiers when defective instances are scarce or unavailable.
Deep Learning for Agile Effort Estimation Have We Solved the Problem Yet?
Jan 14, 2022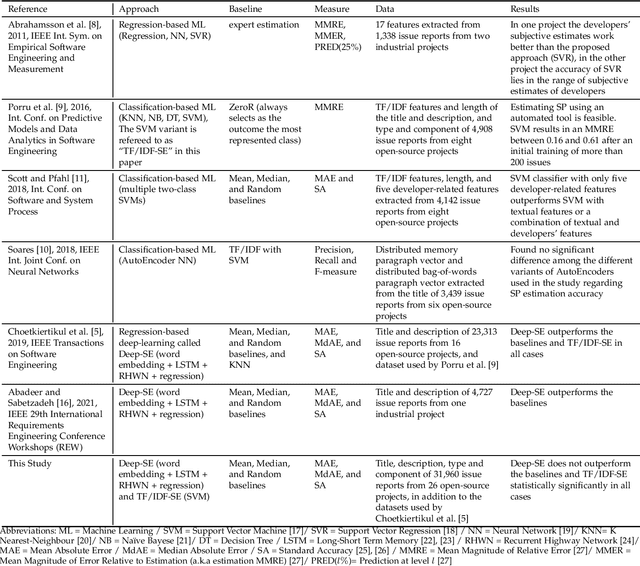
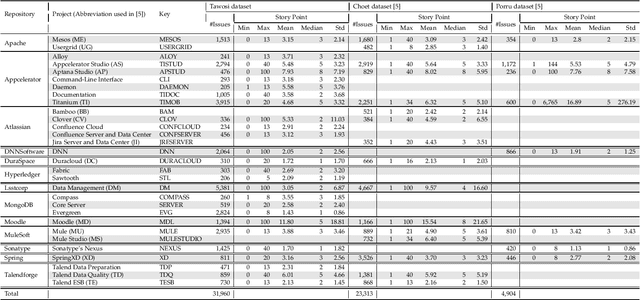
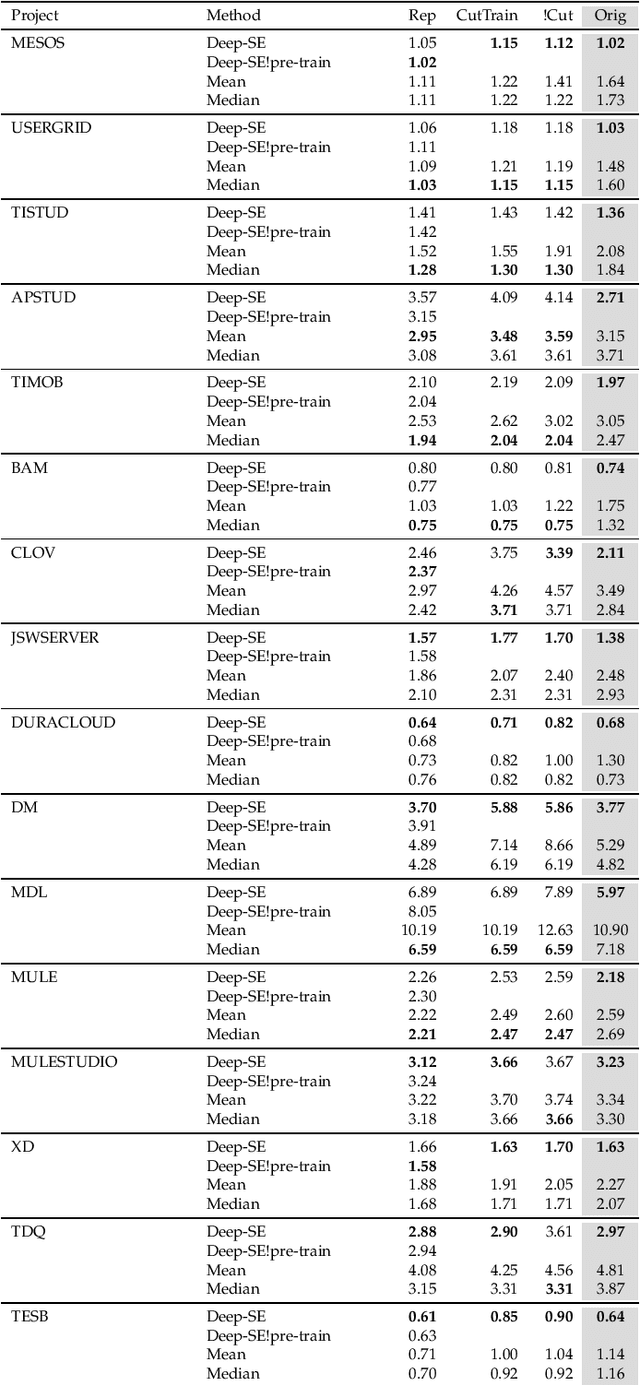
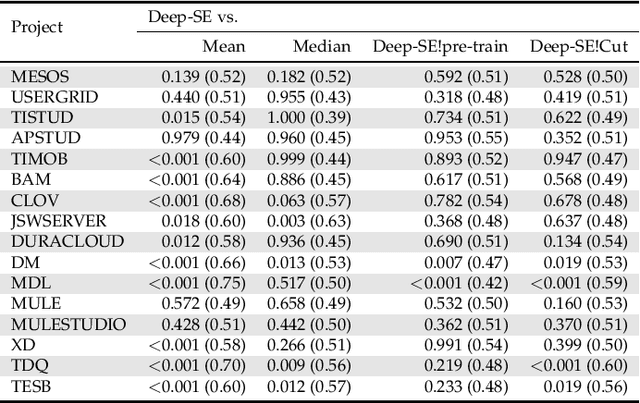
In the last decade, several studies have proposed the use of automated techniques to estimate the effort of agile software development. In this paper we perform a close replication and extension of a seminal work proposing the use of Deep Learning for agile effort estimation (namely Deep-SE), which has set the state-of-the-art since. Specifically, we replicate three of the original research questions aiming at investigating the effectiveness of Deep-SE for both within-project and cross-project effort estimation. We benchmark Deep-SE against three baseline techniques (i.e., Random, Mean and Median effort prediction) and a previously proposed method to estimate agile software project development effort (dubbed TF/IDF-SE), as done in the original study. To this end, we use both the data from the original study and a new larger dataset of 31,960 issues, which we mined from 29 open-source projects. Using more data allows us to strengthen our confidence in the results and further mitigate the threat to the external validity of the study. We also extend the original study by investigating two additional research questions. One evaluates the accuracy of Deep-SE when the training set is augmented with issues from all other projects available in the repository at the time of estimation, and the other examines whether an expensive pre-training step used by the original Deep-SE, has any beneficial effect on its accuracy and convergence speed. The results of our replication show that Deep-SE outperforms the Median baseline estimator and TF/IDF-SE in only very few cases with statistical significance (8/42 and 9/32 cases, respectively), thus confounding previous findings on the efficacy of Deep-SE. The two additional RQs revealed that neither augmenting the training set nor pre-training Deep-SE play a role in improving its accuracy and convergence speed. ...