 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Use of One-Class Support Vector Machine for Software Defect Prediction
Paper and Code
Feb 24, 2022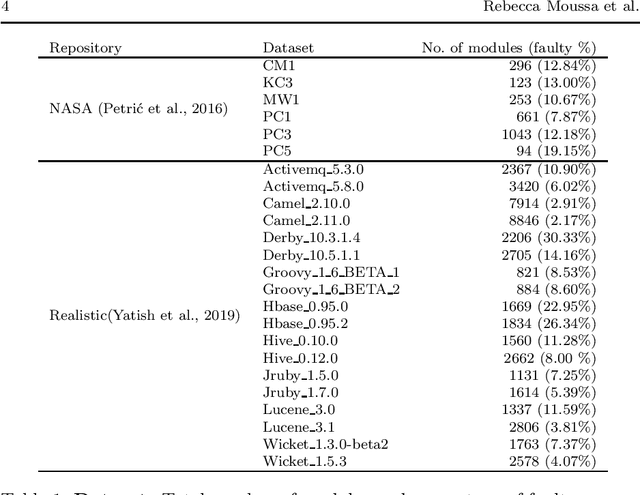

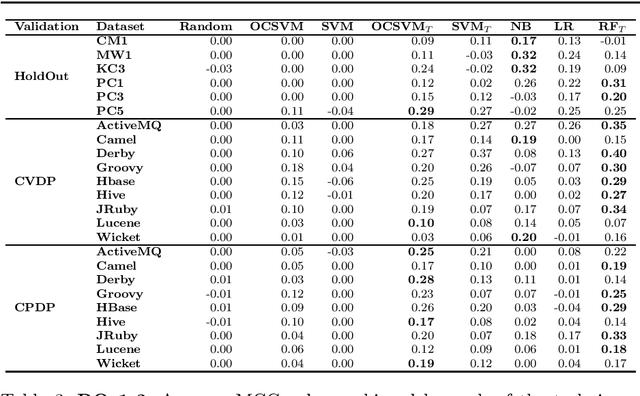
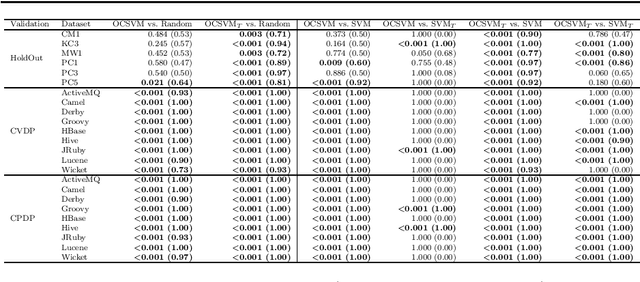
Early software defect identification is considered an important step towards software quality assurance. Software defect prediction aims at identifying software components that are likely to cause faults before a software is made available to the end-user. To date, this task has been modeled as a two-class classification problem, however its nature also allows it to be formulated as a one-class classification task. Preliminary results obtained in prior work show that One-Class Support Vector Machine (OCSVM) can outperform two-class classifiers for defect prediction. If confirmed, these results would overcome the data imbalance problem researchers have for long attempted to tackle in this field. In this paper, we further investigate whether learning from one class only is sufficient to produce effective defect prediction models by conducting a thorough large-scale empirical study investigating 15 real-world software projects, three validation scenarios, eight classifiers, robust evaluation measures and statistical significance tests. The results reveal that OCSVM is more suitable for cross-version and cross-project, rather than for within-project defect prediction, thus suggesting it performs better with heterogeneous data. While, we cannot conclude that OCSVM is the best classifier (Random Forest performs best herein), our results show interesting findings that open up further research avenues for training accurate defect prediction classifiers when defective instances are scarce or unavailable.