 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Drift Visualization of SVM with Shifting Window
Jun 19, 2024



In machine learning, concept drift is an evolution of information that invalidates the current data model. It happens when the statistical properties of the input data change over time in unforeseen ways. Concept drift detection is crucial when dealing with dynamically changing data. Its visualization can bring valuable insight into the data dynamics, especially for multidimensional data, and is related to visual knowledge discovery. We propose a novel visualization model based on parallel coordinates, denoted as parallel histograms through time. Our model represents histograms of feature distributions for successive time-shifted windows. The drift is shown as variations of these histograms, obtained by connecting the means of the distribution for successive time windows. We show how these diagrams can be used to explain the decision made by the machine learning model in choosing the drift point. By isolating the drift at the edges of successive time windows, there will be none (or reduced) drift within the adjacent windows. We illustrate this concept on both synthetic and real datasets. In our experiments, we use an incremental/decremental SVM with shifting window, introduced by us in previous work. With our proposed technique, in addition to detect the presence of concept drift, we can also depict it. This information can be further used to explain the change. mental results, opening the possibility for further investigations.
Emotion Manipulation Through Music -- A Deep Learning Interactive Visual Approach
Jun 12, 2024Music evokes emotion in many people. We introduce a novel way to manipulate the emotional content of a song using AI tools. Our goal is to achieve the desired emotion while leaving the original melody as intact as possible. For this, we create an interactive pipeline capable of shifting an input song into a diametrically opposed emotion and visualize this result through Russel's Circumplex model. Our approach is a proof-of-concept for Semantic Manipulation of Music, a novel field aimed at modifying the emotional content of existing music. We design a deep learning model able to assess the accuracy of our modifications to key, SoundFont instrumentation, and other musical features. The accuracy of our model is in-line with the current state of the art techniques on the 4Q Emotion dataset. With further refinement, this research may contribute to on-demand custom music generation, the automated remixing of existing work, and music playlists tuned for emotional progression.
Information Plane Analysis Visualization in Deep Learning via Transfer Entropy
Apr 01, 2024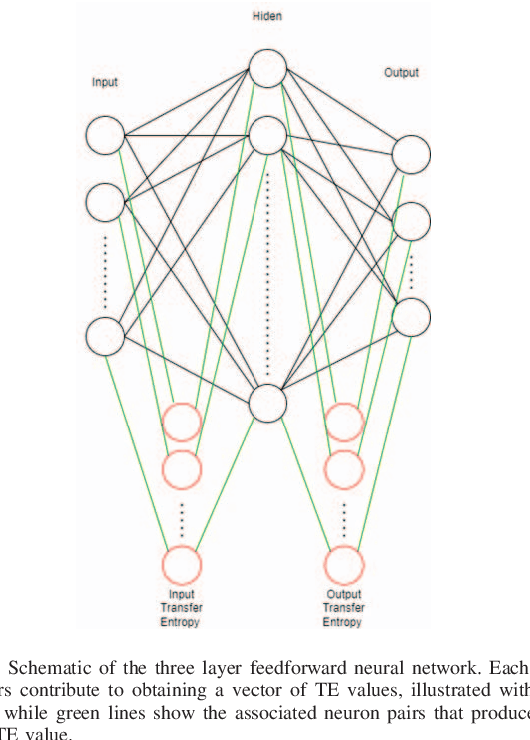
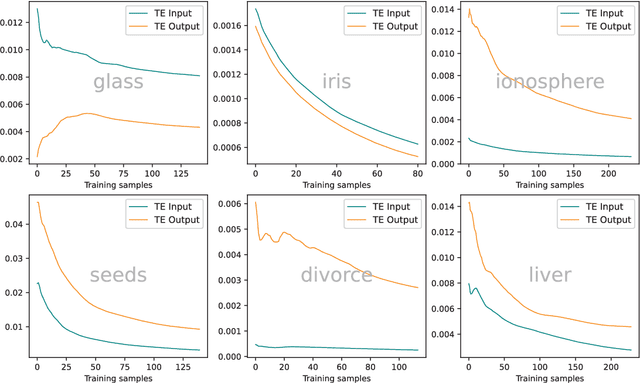
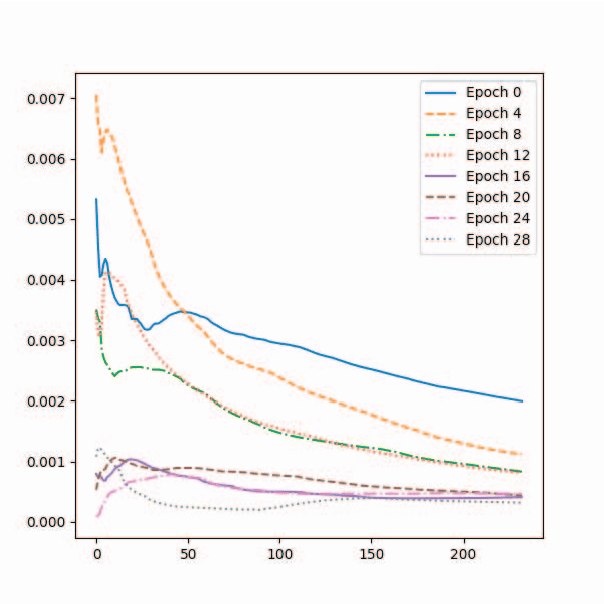
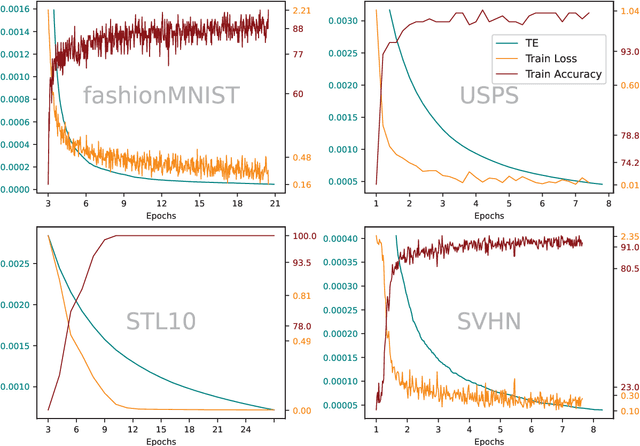
In a feedforward network, Transfer Entropy (TE) can be used to measure the influence that one layer has on another by quantifying the information transfer between them during training. According to the Information Bottleneck principle, a neural model's internal representation should compress the input data as much as possible while still retaining sufficient information about the output. Information Plane analysis is a visualization technique used to understand the trade-off between compression and information preservation in the context of the Information Bottleneck method by plotting the amount of information in the input data against the compressed representation. The claim that there is a causal link between information-theoretic compression and generalization, measured by mutual information, is plausible, but results from different studies are conflicting. In contrast to mutual information, TE can capture temporal relationships between variables. To explore such links, in our novel approach we use TE to quantify information transfer between neural layers and perform Information Plane analysis. We obtained encouraging experimental results, opening the possibility for further investigations.
Accelerating Convolutional Neural Network Pruning via Spatial Aura Entropy
Dec 08, 2023In recent years, pruning has emerged as a popular technique to reduce the computational complexity and memory footprint of Convolutional Neural Network (CNN) models. Mutual Information (MI) has been widely used as a criterion for identifying unimportant filters to prune. However, existing methods for MI computation suffer from high computational cost and sensitivity to noise, leading to suboptimal pruning performance. We propose a novel method to improve MI computation for CNN pruning, using the spatial aura entropy. The spatial aura entropy is useful for evaluating the heterogeneity in the distribution of the neural activations over a neighborhood, providing information about local features. Our method effectively improves the MI computation for CNN pruning, leading to more robust and efficient pruning. Experimental results on the CIFAR-10 benchmark dataset demonstrate the superiority of our approach in terms of pruning performance and computational efficiency.
Pruning Convolutional Filters via Reinforcement Learning with Entropy Minimization
Dec 08, 2023Structural pruning has become an integral part of neural network optimization, used to achieve architectural configurations which can be deployed and run more efficiently on embedded devices. Previous results showed that pruning is possible with minimum performance loss by utilizing a reinforcement learning agent which makes decisions about the sparsity level of each neural layer by maximizing as a reward the accuracy of the network. We introduce a novel information-theoretic reward function which minimizes the spatial entropy of convolutional activations. This minimization ultimately acts as a proxy for maintaining accuracy, although these two criteria are not related in any way. Our method shows that there is another possibility to preserve accuracy without the need to directly optimize it in the agent's reward function. In our experiments, we were able to reduce the total number of FLOPS of multiple popular neural network architectures by 5-10x, incurring minimal or no performance drop and being on par with the solution found by maximizing the accuracy.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
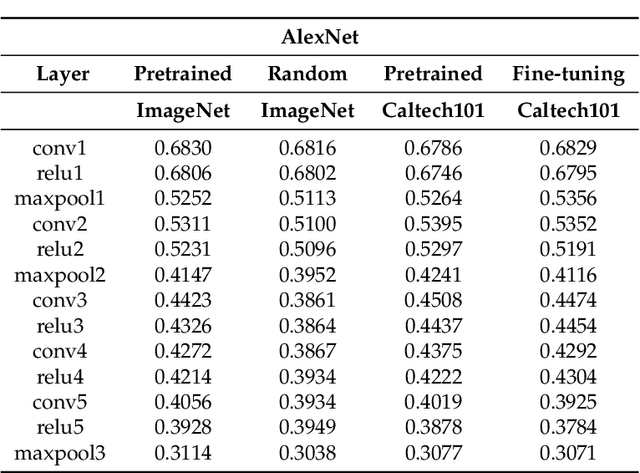
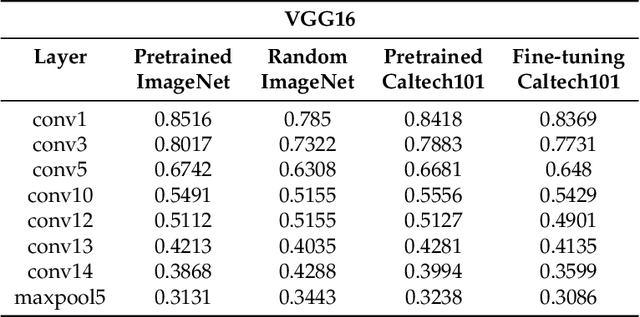
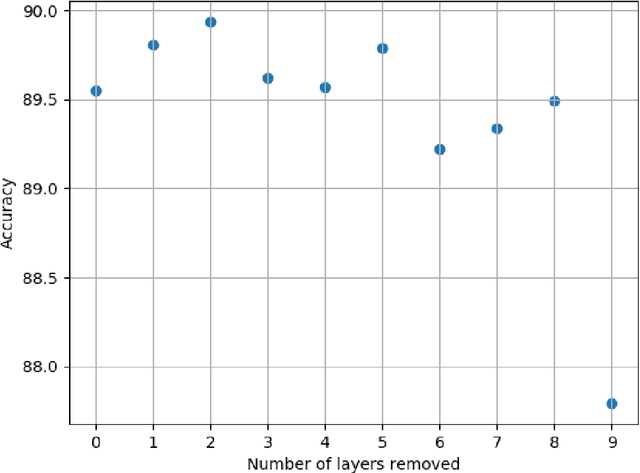
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.
Weighted Random Search for Hyperparameter Optimization
Apr 03, 2020
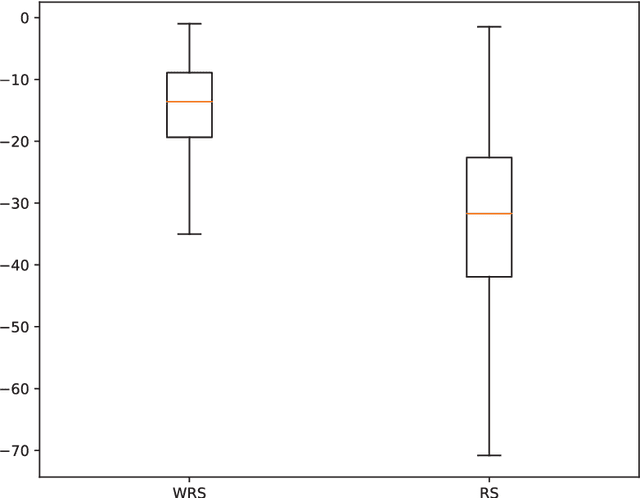

We introduce an improved version of Random Search (RS), used here for hyperparameter optimization of machine learning algorithms. Unlike the standard RS, which generates for each trial new values for all hyperparameters, we generate new values for each hyperparameter with a probability of change. The intuition behind our approach is that a value that already triggered a good result is a good candidate for the next step, and should be tested in new combinations of hyperparameter values. Within the same computational budget, our method yields better results than the standard RS. Our theoretical results prove this statement. We test our method on a variation of one of the most commonly used objective function for this class of problems (the Grievank function) and for the hyperparameter optimization of a deep learning CNN architecture. Our results can be generalized to any optimization problem defined on a discrete domain.
* 14 pages, 5 figures, journal paper
Weighted Random Search for CNN Hyperparameter Optimization
Mar 30, 2020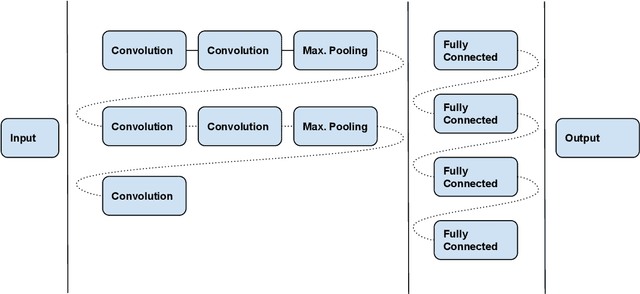

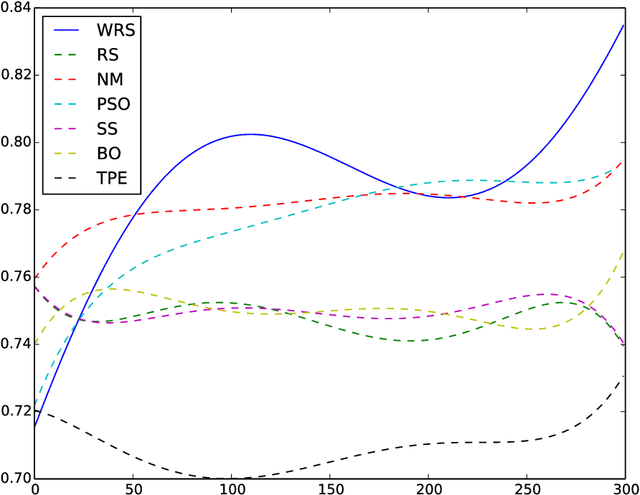
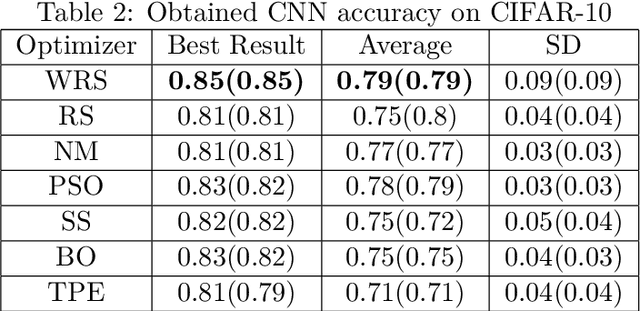
Nearly all model algorithms used in machine learning use two different sets of parameters: the training parameters and the meta-parameters (hyperparameters). While the training parameters are learned during the training phase, the values of the hyperparameters have to be specified before learning starts. For a given dataset, we would like to find the optimal combination of hyperparameter values, in a reasonable amount of time. This is a challenging task because of its computational complexity. In previous work [11], we introduced the Weighted Random Search (WRS) method, a combination of Random Search (RS) and probabilistic greedy heuristic. In the current paper, we compare the WRS method with several state-of-the art hyperparameter optimization methods with respect to Convolutional Neural Network (CNN) hyperparameter optimization. The criterion is the classification accuracy achieved within the same number of tested combinations of hyperparameter values. According to our experiments, the WRS algorithm outperforms the other methods.
* 11 pages, 2 figurs, journal article