 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Convolutional Filters via Reinforcement Learning with Entropy Minimization
Dec 08, 2023Structural pruning has become an integral part of neural network optimization, used to achieve architectural configurations which can be deployed and run more efficiently on embedded devices. Previous results showed that pruning is possible with minimum performance loss by utilizing a reinforcement learning agent which makes decisions about the sparsity level of each neural layer by maximizing as a reward the accuracy of the network. We introduce a novel information-theoretic reward function which minimizes the spatial entropy of convolutional activations. This minimization ultimately acts as a proxy for maintaining accuracy, although these two criteria are not related in any way. Our method shows that there is another possibility to preserve accuracy without the need to directly optimize it in the agent's reward function. In our experiments, we were able to reduce the total number of FLOPS of multiple popular neural network architectures by 5-10x, incurring minimal or no performance drop and being on par with the solution found by maximizing the accuracy.
Accelerating Convolutional Neural Network Pruning via Spatial Aura Entropy
Dec 08, 2023In recent years, pruning has emerged as a popular technique to reduce the computational complexity and memory footprint of Convolutional Neural Network (CNN) models. Mutual Information (MI) has been widely used as a criterion for identifying unimportant filters to prune. However, existing methods for MI computation suffer from high computational cost and sensitivity to noise, leading to suboptimal pruning performance. We propose a novel method to improve MI computation for CNN pruning, using the spatial aura entropy. The spatial aura entropy is useful for evaluating the heterogeneity in the distribution of the neural activations over a neighborhood, providing information about local features. Our method effectively improves the MI computation for CNN pruning, leading to more robust and efficient pruning. Experimental results on the CIFAR-10 benchmark dataset demonstrate the superiority of our approach in terms of pruning performance and computational efficiency.
Semiotic Aggregation in Deep Learning
Apr 22, 2021
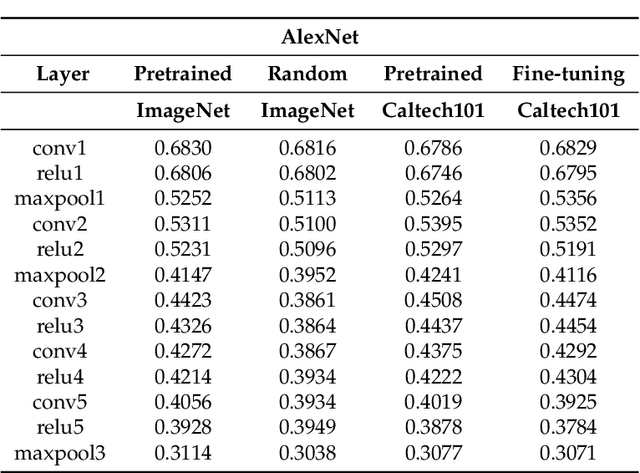
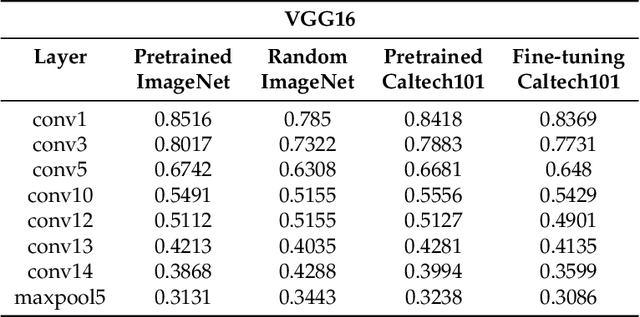
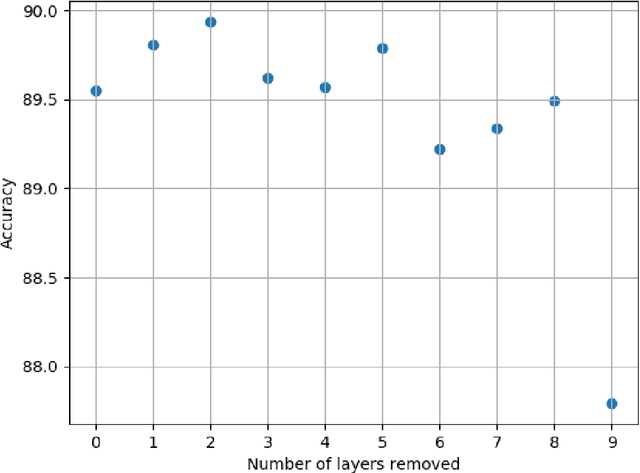
Convolutional neural networks utilize a hierarchy of neural network layers. The statistical aspects of information concentration in successive layers can bring an insight into the feature abstraction process. We analyze the saliency maps of these layers from the perspective of semiotics, also known as the study of signs and sign-using behavior. In computational semiotics, this aggregation operation (known as superization) is accompanied by a decrease of spatial entropy: signs are aggregated into supersign. Using spatial entropy, we compute the information content of the saliency maps and study the superization processes which take place between successive layers of the network. In our experiments, we visualize the superization process and show how the obtained knowledge can be used to explain the neural decision model. In addition, we attempt to optimize the architecture of the neural model employing a semiotic greedy technique. To the extent of our knowledge, this is the first application of computational semiotics in the analysis and interpretation of deep neural networks.