 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarlow Graph Auto-Encoder for Unsupervised Network Embedding
Nov 23, 2021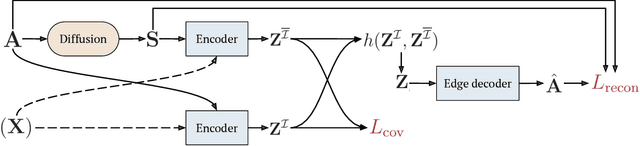

Network embedding has emerged as a promising research field for network analysis. Recently, an approach, named Barlow Twins, has been proposed for self-supervised learning in computer vision by applying the redundancy-reduction principle to the embedding vectors corresponding to two distorted versions of the image samples. Motivated by this, we propose Barlow Graph Auto-Encoder, a simple yet effective architecture for learning network embedding. It aims to maximize the similarity between the embedding vectors of immediate and larger neighborhoods of a node, while minimizing the redundancy between the components of these projections. In addition, we also present the variation counterpart named as Barlow Variational Graph Auto-Encoder. Our approach yields promising results for inductive link prediction and is also on par with state of the art for clustering and downstream node classification, as demonstrated by extensive comparisons with several well-known techniques on three benchmark citation datasets.
A Framework for Joint Unsupervised Learning of Cluster-Aware Embedding for Heterogeneous Networks
Aug 09, 2021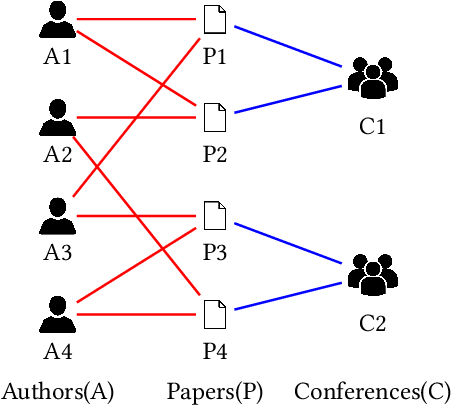

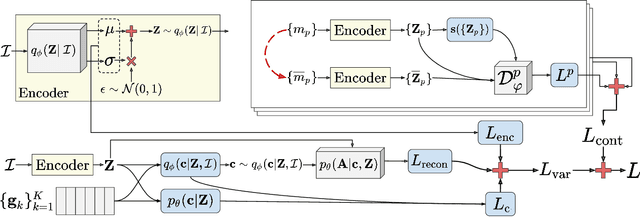
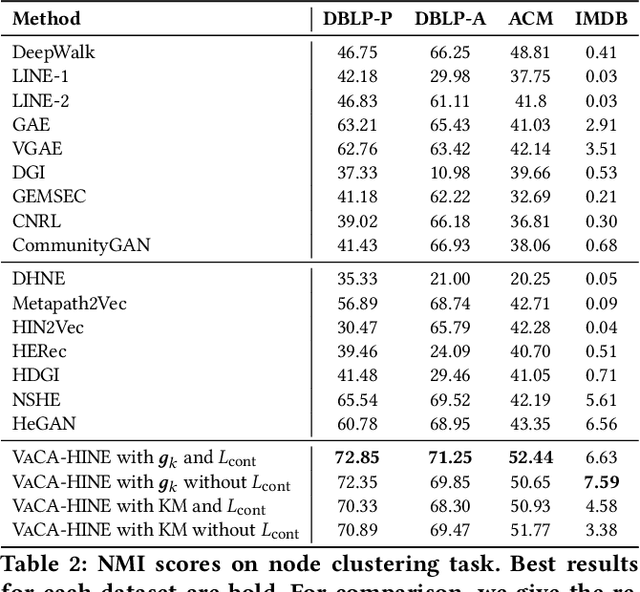
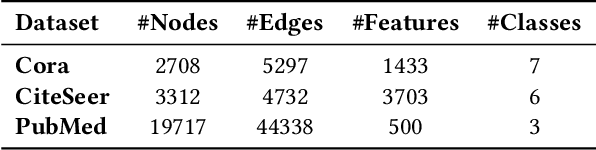
Heterogeneous Information Network (HIN) embedding refers to the low-dimensional projections of the HIN nodes that preserve the HIN structure and semantics. HIN embedding has emerged as a promising research field for network analysis as it enables downstream tasks such as clustering and node classification. In this work, we propose \ours for joint learning of cluster embeddings as well as cluster-aware HIN embedding. We assume that the connected nodes are highly likely to fall in the same cluster, and adopt a variational approach to preserve the information in the pairwise relations in a cluster-aware manner. In addition, we deploy contrastive modules to simultaneously utilize the information in multiple meta-paths, thereby alleviating the meta-path selection problem - a challenge faced by many of the famous HIN embedding approaches. The HIN embedding, thus learned, not only improves the clustering performance but also preserves pairwise proximity as well as the high-order HIN structure. We show the effectiveness of our approach by comparing it with many competitive baselines on three real-world datasets on clustering and downstream node classification.
Variational Embeddings for Community Detection and Node Representation
Jan 11, 2021
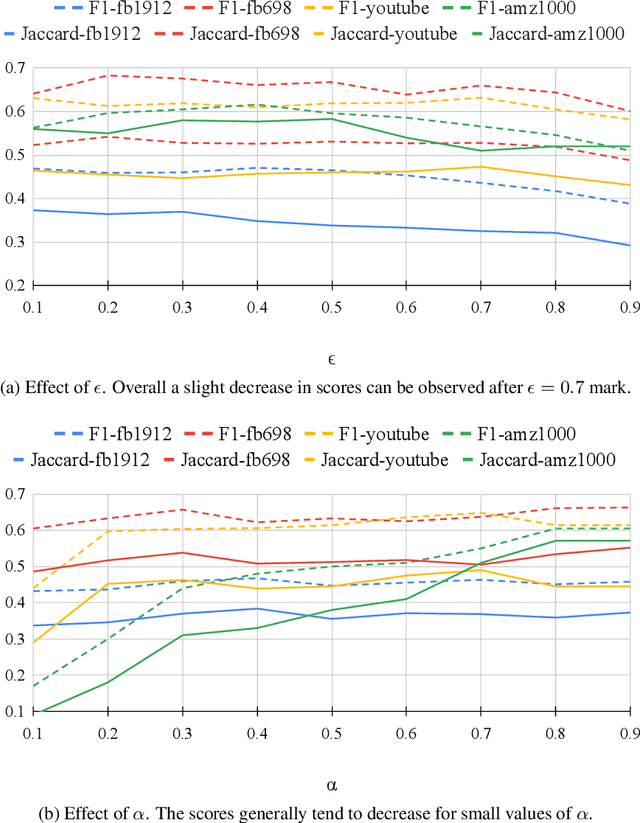
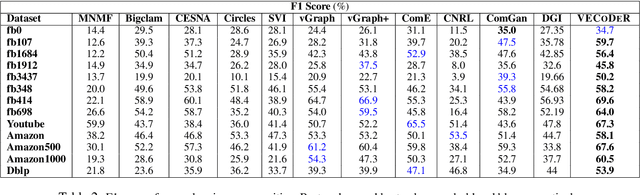
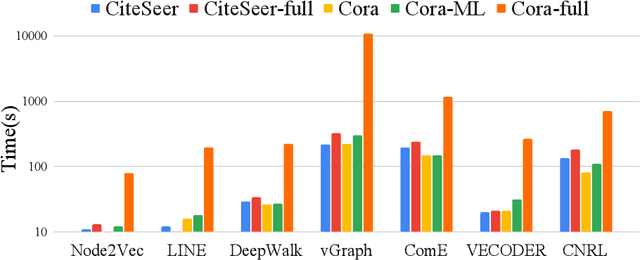
In this paper, we study how to simultaneously learn two highly correlated tasks of graph analysis, i.e., community detection and node representation learning. We propose an efficient generative model called VECoDeR for jointly learning Variational Embeddings for Community Detection and node Representation. VECoDeR assumes that every node can be a member of one or more communities. The node embeddings are learned in such a way that connected nodes are not only "closer" to each other but also share similar community assignments. A joint learning framework leverages community-aware node embeddings for better community detection. We demonstrate on several graph datasets that VECoDeR effectively out-performs many competitive baselines on all three tasks i.e. node classification, overlapping community detection and non-overlapping community detection. We also show that VECoDeR is computationally efficient and has quite robust performance with varying hyperparameters.
Epitomic Variational Graph Autoencoder
Apr 03, 2020

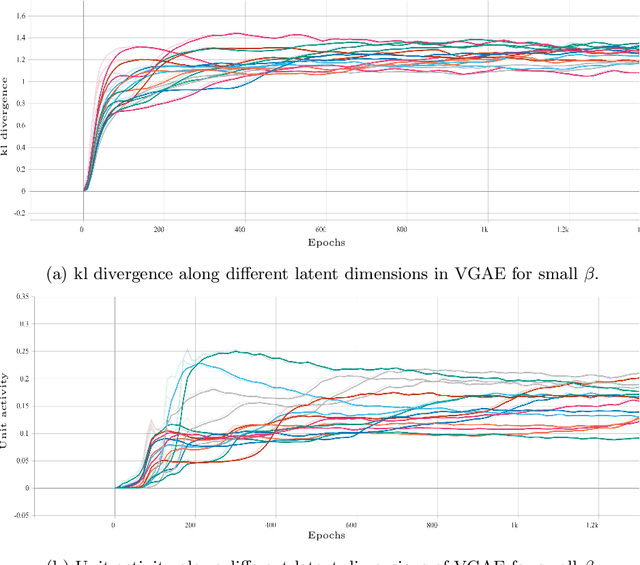

Variational autoencoder (VAE) is a widely used generative model for unsupervised learning of vector data. The learning capacity of VAE is often limited by \textit{over-pruning} - a phenomenon that prevents many of the latent dimensions from learning any useful information about the input data. Variational graph autoencoder (VGAE) extends VAE for unsupervised learning of graph-structured data. Being an extension of VAE model, VGAE, also suffers from over-pruning in principal. In this paper we look at over-pruning in VGAE and observe that the generative capacity of VGAE is limited because of the way VGAE deals with this issue. We then propose epitomic variational graph autoencoder (EVGAE), a generative variational framework for graph datasets to overcome over-pruning. We show through experiments that the resulting model has a better generative ability and also achieves better scores in graph analysis related tasks.
Clustering with Simultaneous Local and Global View of Data: A message passing based approach
Mar 12, 2018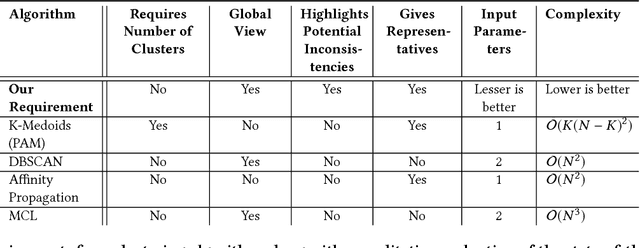
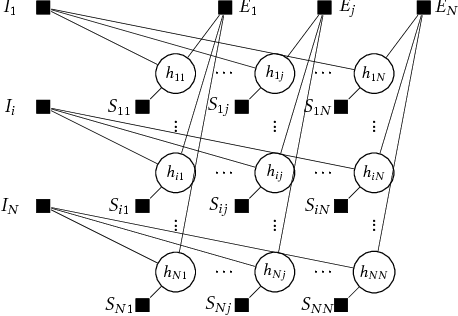
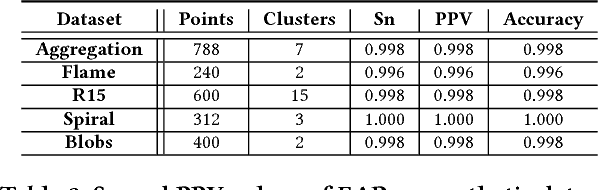
A good clustering algorithm should not only be able to discover clusters of arbitrary shapes (global view) but also provide additional information, which can be used to gain more meaningful insights into the internal structure of the clusters (local view). In this work we use the mathematical framework of factor graphs and message passing algorithms to optimize a pairwise similarity based cost function, in the same spirit as was done in Affinity Propagation. Using this framework we develop two variants of a new clustering algorithm, EAP and SHAPE. EAP/SHAPE can not only discover clusters of arbitrary shapes but also provide a rich local view in the form of meaningful local representatives (exemplars) and connections between these local exemplars. We discuss how this local information can be used to gain various insights about the clusters including varying relative cluster densities and indication of local strength in different regions of a cluster . We also discuss how this can help an analyst in discovering and resolving potential inconsistencies in the results. The efficacy of EAP/SHAPE is shown by applying it to various synthetic and real world benchmark datasets.