 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Network for Elderly Wandering Prediction in Indoor Scenarios
Dec 23, 2020



This work proposes a way to detect the wandering activity of Alzheimer's patients from path data collected from non-intrusive indoor sensors around the house. Due to the lack of adequate data, we've manually generated a dataset of 220 paths using our own developed application. Wandering patterns in the literature are normally identified by visual features (such as loops or random movement), thus our dataset was transformed into images and augmented. Convolutional layers were used on the neural network model since they tend to have good results finding patterns, especially on images. The Convolutional Neural Network model was trained with the generated data and achieved an f1 score (relation between precision and recall) of 75%, recall of 60%, and precision of 100% on our 10 sample validation slice
A Bimodal Learning Approach to Assist Multi-sensory Effects Synchronization
Apr 28, 2018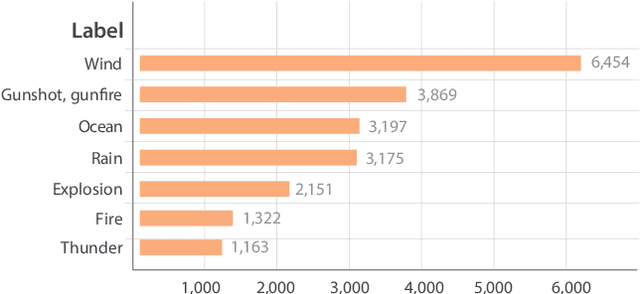
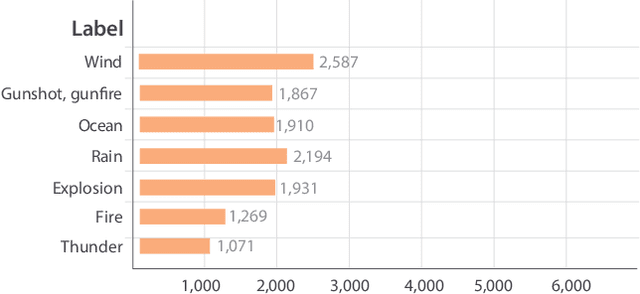
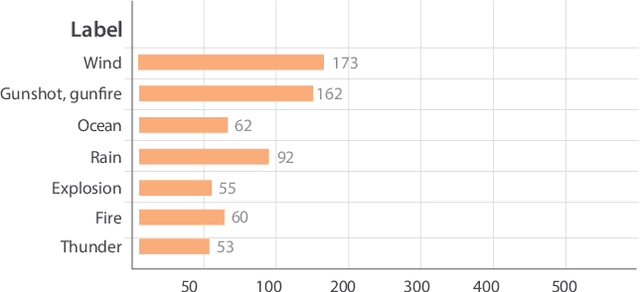
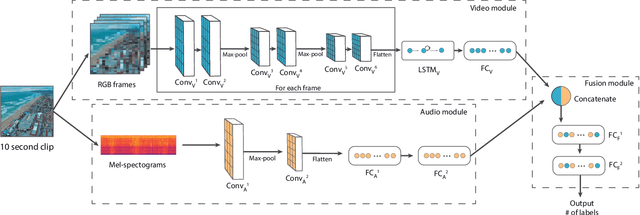
In mulsemedia applications, traditional media content (text, image, audio, video, etc.) can be related to media objects that target other human senses (e.g., smell, haptics, taste). Such applications aim at bridging the virtual and real worlds through sensors and actuators. Actuators are responsible for the execution of sensory effects (e.g., wind, heat, light), which produce sensory stimulations on the users. In these applications sensory stimulation must happen in a timely manner regarding the other traditional media content being presented. For example, at the moment in which an explosion is presented in the audiovisual content, it may be adequate to activate actuators that produce heat and light. It is common to use some declarative multimedia authoring language to relate the timestamp in which each media object is to be presented to the execution of some sensory effect. One problem in this setting is that the synchronization of media objects and sensory effects is done manually by the author(s) of the application, a process which is time-consuming and error prone. In this paper, we present a bimodal neural network architecture to assist the synchronization task in mulsemedia applications. Our approach is based on the idea that audio and video signals can be used simultaneously to identify the timestamps in which some sensory effect should be executed. Our learning architecture combines audio and video signals for the prediction of scene components. For evaluation purposes, we construct a dataset based on Google's AudioSet. We provide experiments to validate our bimodal architecture. Our results show that the bimodal approach produces better results when compared to several variants of unimodal architectures.