 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Approach to Automatic Fall Detection of Combat Soldiers
Jan 26, 2025



Military personnel and security agents often face significant physical risks during conflict and engagement situations, particularly in urban operations. Ensuring the rapid and accurate communication of incidents involving injuries is crucial for the timely execution of rescue operations. This article presents research conducted under the scope of the Brazilian Navy's ``Soldier of the Future'' project, focusing on the development of a Casualty Detection System to identify injuries that could incapacitate a soldier and lead to severe blood loss. The study specifically addresses the detection of soldier falls, which may indicate critical injuries such as hypovolemic hemorrhagic shock. To generate the publicly available dataset, we used smartwatches and smartphones as wearable devices to collect inertial data from soldiers during various activities, including simulated falls. The data were used to train 1D Convolutional Neural Networks (CNN1D) with the objective of accurately classifying falls that could result from life-threatening injuries. We explored different sensor placements (on the wrists and near the center of mass) and various approaches to using inertial variables, including linear and angular accelerations. The neural network models were optimized using Bayesian techniques to enhance their performance. The best-performing model and its results, discussed in this article, contribute to the advancement of automated systems for monitoring soldier safety and improving response times in engagement scenarios.
A Bimodal Learning Approach to Assist Multi-sensory Effects Synchronization
Apr 28, 2018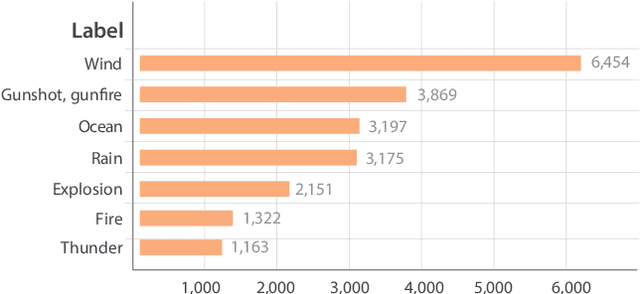
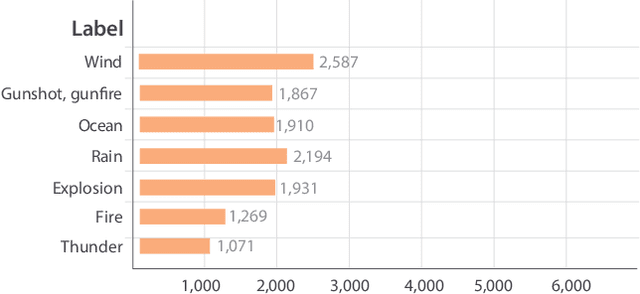
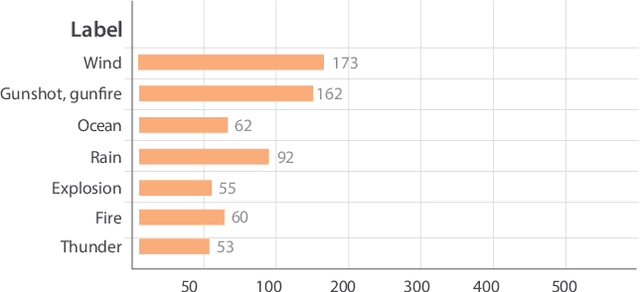
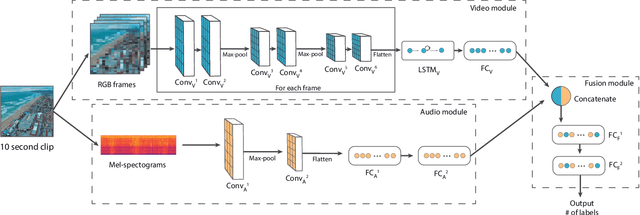
In mulsemedia applications, traditional media content (text, image, audio, video, etc.) can be related to media objects that target other human senses (e.g., smell, haptics, taste). Such applications aim at bridging the virtual and real worlds through sensors and actuators. Actuators are responsible for the execution of sensory effects (e.g., wind, heat, light), which produce sensory stimulations on the users. In these applications sensory stimulation must happen in a timely manner regarding the other traditional media content being presented. For example, at the moment in which an explosion is presented in the audiovisual content, it may be adequate to activate actuators that produce heat and light. It is common to use some declarative multimedia authoring language to relate the timestamp in which each media object is to be presented to the execution of some sensory effect. One problem in this setting is that the synchronization of media objects and sensory effects is done manually by the author(s) of the application, a process which is time-consuming and error prone. In this paper, we present a bimodal neural network architecture to assist the synchronization task in mulsemedia applications. Our approach is based on the idea that audio and video signals can be used simultaneously to identify the timestamps in which some sensory effect should be executed. Our learning architecture combines audio and video signals for the prediction of scene components. For evaluation purposes, we construct a dataset based on Google's AudioSet. We provide experiments to validate our bimodal architecture. Our results show that the bimodal approach produces better results when compared to several variants of unimodal architectures.