 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking the Imposters: In-Domain Detection of Human vs. Machine-Generated Tweets
Jun 25, 2024The rapid development of large language models (LLMs) has significantly improved the generation of fluent and convincing text, raising concerns about their misuse on social media platforms. We present a methodology using Twitter datasets to examine the generative capabilities of four LLMs: Llama 3, Mistral, Qwen2, and GPT4o. We evaluate 7B and 8B parameter base-instruction models of the three open-source LLMs and validate the impact of further fine-tuning and "uncensored" versions. Our findings show that "uncensored" models with additional in-domain fine-tuning dramatically reduce the effectiveness of automated detection methods. This study addresses a gap by exploring smaller open-source models and the effects of "uncensoring," providing insights into how fine-tuning and content moderation influence machine-generated text detection.
A Roadmap for Multilingual, Multimodal Domain Independent Deception Detection
May 07, 2024
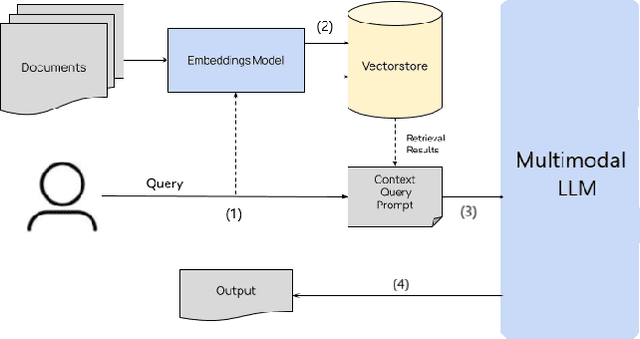
Deception, a prevalent aspect of human communication, has undergone a significant transformation in the digital age. With the globalization of online interactions, individuals are communicating in multiple languages and mixing languages on social media, with varied data becoming available in each language and dialect. At the same time, the techniques for detecting deception are similar across the board. Recent studies have shown the possibility of the existence of universal linguistic cues to deception across domains within the English language; however, the existence of such cues in other languages remains unknown. Furthermore, the practical task of deception detection in low-resource languages is not a well-studied problem due to the lack of labeled data. Another dimension of deception is multimodality. For example, a picture with an altered caption in fake news or disinformation may exist. This paper calls for a comprehensive investigation into the complexities of deceptive language across linguistic boundaries and modalities within the realm of computer security and natural language processing and the possibility of using multilingual transformer models and labeled data in various languages to universally address the task of deception detection.
* 6 pages, 1 figure, shorter version in SIAM International Conference on Data Mining (SDM) 2024
Homograph Attacks on Maghreb Sentiment Analyzers
Feb 05, 2024We examine the impact of homograph attacks on the Sentiment Analysis (SA) task of different Arabic dialects from the Maghreb North-African countries. Homograph attacks result in a 65.3% decrease in transformer classification from an F1-score of 0.95 to 0.33 when data is written in "Arabizi". The goal of this study is to highlight LLMs weaknesses' and to prioritize ethical and responsible Machine Learning.
Domain-Independent Deception: A New Taxonomy and Linguistic Analysis
Feb 01, 2024Internet-based economies and societies are drowning in deceptive attacks. These attacks take many forms, such as fake news, phishing, and job scams, which we call ``domains of deception.'' Machine-learning and natural-language-processing researchers have been attempting to ameliorate this precarious situation by designing domain-specific detectors. Only a few recent works have considered domain-independent deception. We collect these disparate threads of research and investigate domain-independent deception. First, we provide a new computational definition of deception and break down deception into a new taxonomy. Then, we analyze the debate on linguistic cues for deception and supply guidelines for systematic reviews. Finally, we investigate common linguistic features and give evidence for knowledge transfer across different forms of deception.
Claim Verification using a Multi-GAN based Model
Mar 24, 2021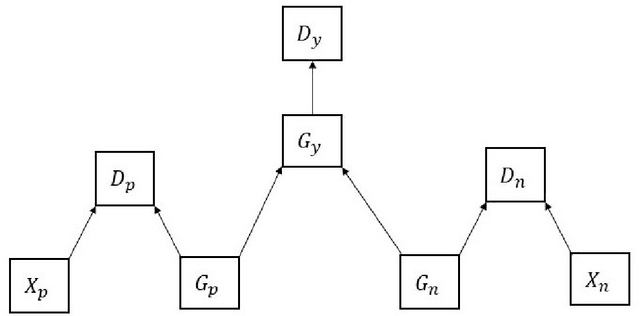
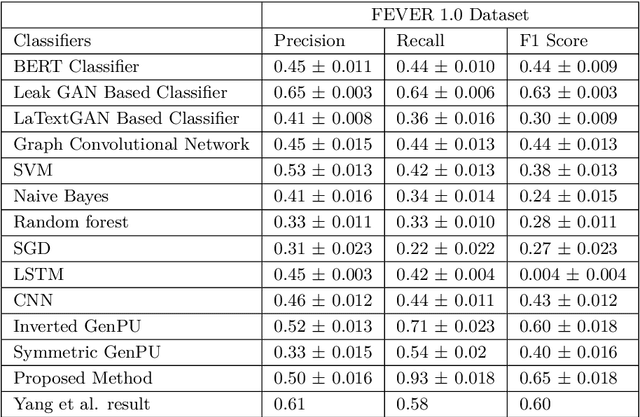
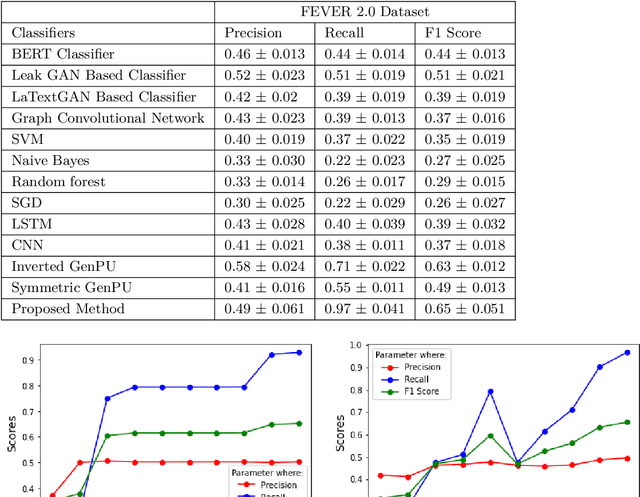
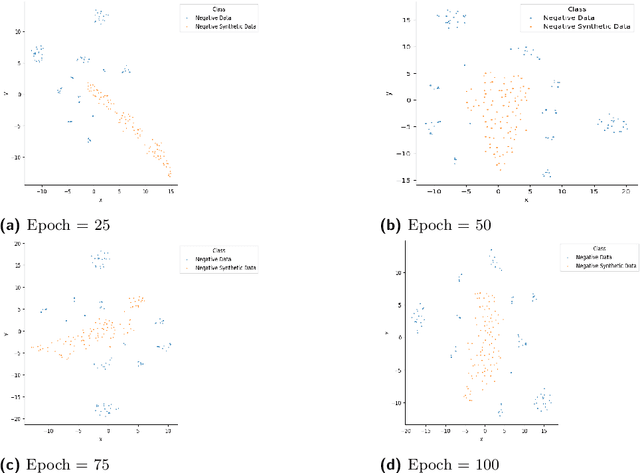
This article describes research on claim verification carried out using a multiple GAN-based model. The proposed model consists of three pairs of generators and discriminators. The generator and discriminator pairs are responsible for generating synthetic data for supported and refuted claims and claim labels. A theoretical discussion about the proposed model is provided to validate the equilibrium state of the model. The proposed model is applied to the FEVER dataset, and a pre-trained language model is used for the input text data. The synthetically generated data helps to gain information which helps the model to perform better than state of the art models and other standard classifiers.
Modeling Coherency in Generated Emails by Leveraging Deep Neural Learners
Jul 14, 2020

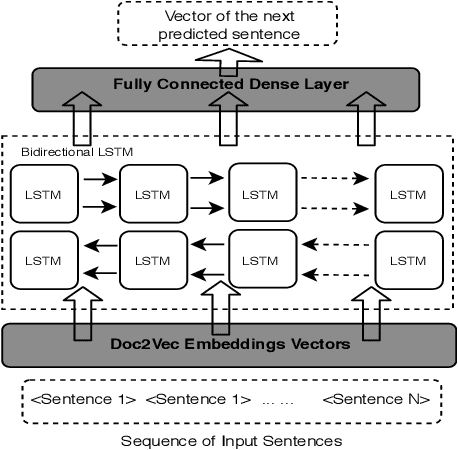
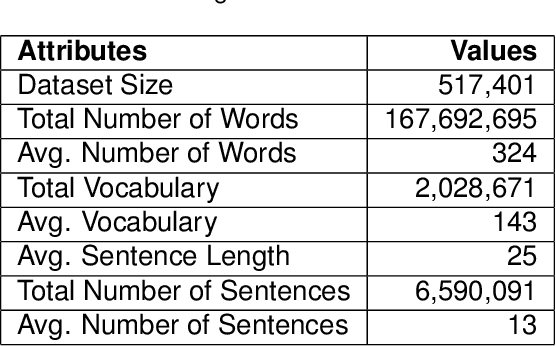
Advanced machine learning and natural language techniques enable attackers to launch sophisticated and targeted social engineering-based attacks. To counter the active attacker issue, researchers have since resorted to proactive methods of detection. Email masquerading using targeted emails to fool the victim is an advanced attack method. However automatic text generation requires controlling the context and coherency of the generated content, which has been identified as an increasingly difficult problem. The method used leverages a hierarchical deep neural model which uses a learned representation of the sentences in the input document to generate structured written emails. We demonstrate the generation of short and targeted text messages using the deep model. The global coherency of the synthesized text is evaluated using a qualitative study as well as multiple quantitative measures.