 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks
Oct 31, 2025As Natural Language Generation (NLG) continues to be widely adopted, properly assessing it has become quite difficult. Lately, using large language models (LLMs) for evaluating these generations has gained traction, as they tend to align more closely with human preferences than conventional n-gram or embedding-based metrics. In our experiments, we show that LLM judges have low intra-rater reliability in their assigned scores across different runs. This variance makes their ratings inconsistent, almost arbitrary in the worst case, making it difficult to measure how good their judgments actually are. We quantify this inconsistency across different NLG tasks and benchmarks and see if judicious use of LLM judges can still be useful following proper guidelines.
Analyzing the Performance of Large Language Models on Code Summarization
Apr 10, 2024Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
A Multi-Perspective Architecture for Semantic Code Search
May 06, 2020

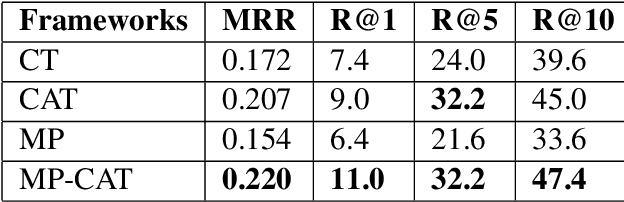

The ability to match pieces of code to their corresponding natural language descriptions and vice versa is fundamental for natural language search interfaces to software repositories. In this paper, we propose a novel multi-perspective cross-lingual neural framework for code--text matching, inspired in part by a previous model for monolingual text-to-text matching, to capture both global and local similarities. Our experiments on the CoNaLa dataset show that our proposed model yields better performance on this cross-lingual text-to-code matching task than previous approaches that map code and text to a single joint embedding space.