 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Soft Inducement Framework for Incentive-Aided Steering of No-Regret Players
Aug 29, 2025In this work, we investigate a steering problem in a mediator-augmented two-player normal-form game, where the mediator aims to guide players toward a specific action profile through information and incentive design. We first characterize the games for which successful steering is possible. Moreover, we establish that steering players to any desired action profile is not always achievable with information design alone, nor when accompanied with sublinear payment schemes. Consequently, we derive a lower bound on the constant payments required per round to achieve this goal. To address these limitations incurred with information design, we introduce an augmented approach that involves a one-shot information design phase before the start of the repeated game, transforming the prior interaction into a Stackelberg game. Finally, we theoretically demonstrate that this approach improves the convergence rate of players' action profiles to the target point by a constant factor with high probability, and support it with empirical results.
Remote Estimation Games with Random Walk Processes: Stackelberg Equilibrium
Dec 01, 2024Remote estimation is a crucial element of real time monitoring of a stochastic process. While most of the existing works have concentrated on obtaining optimal sampling strategies, motivated by malicious attacks on cyber-physical systems, we model sensing under surveillance as a game between an attacker and a defender. This introduces strategic elements to conventional remote estimation problems. Additionally, inspired by increasing detection capabilities, we model an element of information leakage for each player. Parameterizing the game in terms of uncertainty on each side, information leakage, and cost of sampling, we consider the Stackelberg Equilibrium (SE) concept where one of the players acts as the leader and the other one as the follower. By focusing our attention on stationary probabilistic sampling policies, we characterize the SE of this game and provide simulations to show the efficacy of our results.
Learning How to Strategically Disclose Information
Mar 13, 2024Strategic information disclosure, in its simplest form, considers a game between an information provider (sender) who has access to some private information that an information receiver is interested in. While the receiver takes an action that affects the utilities of both players, the sender can design information (or modify beliefs) of the receiver through signal commitment, hence posing a Stackelberg game. However, obtaining a Stackelberg equilibrium for this game traditionally requires the sender to have access to the receiver's objective. In this work, we consider an online version of information design where a sender interacts with a receiver of an unknown type who is adversarially chosen at each round. Restricting attention to Gaussian prior and quadratic costs for the sender and the receiver, we show that $\mathcal{O}(\sqrt{T})$ regret is achievable with full information feedback, where $T$ is the total number of interactions between the sender and the receiver. Further, we propose a novel parametrization that allows the sender to achieve $\mathcal{O}(\sqrt{T})$ regret for a general convex utility function. We then consider the Bayesian Persuasion problem with an additional cost term in the objective function, which penalizes signaling policies that are more informative and obtain $\mathcal{O}(\log(T))$ regret. Finally, we establish a sublinear regret bound for the partial information feedback setting and provide simulations to support our theoretical results.
Secure Byzantine-Robust Distributed Learning via Clustering
Oct 06, 2021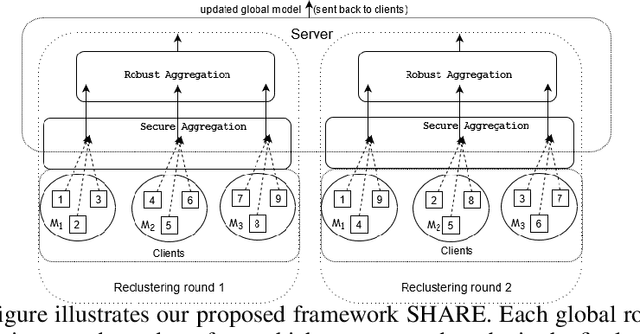
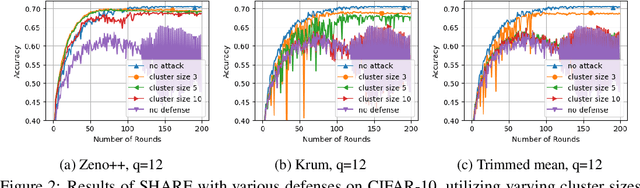
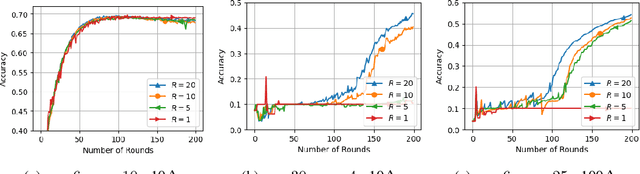
Federated learning systems that jointly preserve Byzantine robustness and privacy have remained an open problem. Robust aggregation, the standard defense for Byzantine attacks, generally requires server access to individual updates or nonlinear computation -- thus is incompatible with privacy-preserving methods such as secure aggregation via multiparty computation. To this end, we propose SHARE (Secure Hierarchical Robust Aggregation), a distributed learning framework designed to cryptographically preserve client update privacy and robustness to Byzantine adversaries simultaneously. The key idea is to incorporate secure averaging among randomly clustered clients before filtering malicious updates through robust aggregation. Experiments show that SHARE has similar robustness guarantees as existing techniques while enhancing privacy.